Simplicity in the Philosophy of Science
The view that simplicity is a virtue in scientific theories and that, other things being equal, simpler theories should be preferred to more complex ones has been widely advocated in the history of science and philosophy, and it remains widely held by modern scientists and philosophers of science. It often goes by the name of “Ockham’s Razor.” The claim is that simplicity ought to be one of the key criteria for evaluating and choosing between rival theories, alongside criteria such as consistency with the data and coherence with accepted background theories. Simplicity, in this sense, is often understood ontologically, in terms of how simple a theory represents nature as being—for example, a theory might be said to be simpler than another if it posits the existence of fewer entities, causes, or processes in nature in order to account for the empirical data. However, simplicity can also been understood in terms of various features of how theories go about explaining nature—for example, a theory might be said to be simpler than another if it contains fewer adjustable parameters, if it invokes fewer extraneous assumptions, or if it provides a more unified explanation of the data.
Preferences for simpler theories are widely thought to have played a central role in many important episodes in the history of science. Simplicity considerations are also regarded as integral to many of the standard methods that scientists use for inferring hypotheses from empirical data, the most of common illustration of this being the practice of curve-fitting. Indeed, some philosophers have argued that a systematic bias towards simpler theories and hypotheses is a fundamental component of inductive reasoning quite generally.
However, though the legitimacy of choosing between rival scientific theories on grounds of simplicity is frequently taken for granted, or viewed as self-evident, this practice raises a number of very difficult philosophical problems. A common concern is that notions of simplicity appear vague, and judgments about the relative simplicity of particular theories appear irredeemably subjective. Thus, one problem is to explain more precisely what it is for theories to be simpler than others and how, if at all, the relative simplicity of theories can be objectively measured. In addition, even if we can get clearer about what simplicity is and how it is to be measured, there remains the problem of explaining what justification, if any, can be provided for choosing between rival scientific theories on grounds of simplicity. For instance, do we have any reason for thinking that simpler theories are more likely to be true?
This article provides an overview of the debate over simplicity in the philosophy of science. Section 1 illustrates the putative role of simplicity considerations in scientific methodology, outlining some common views of scientists on this issue, different formulations of Ockham’s Razor, and some commonly cited examples of simplicity at work in the history and current practice of science. Section 2 highlights the wider significance of the philosophical issues surrounding simplicity for central controversies in the philosophy of science and epistemology. Section 3 outlines the challenges facing the project of trying to precisely define and measure theoretical simplicity, and it surveys the leading measures of simplicity and complexity currently on the market. Finally, Section 4 surveys the wide variety of attempts that have been made to justify the practice of choosing between rival theories on grounds of simplicity.
Table of Contents
- The Role of Simplicity in Science
- Wider Philosophical Significance of Issues Surrounding Simplicity
- Defining and Measuring Simplicity
- Justifying Preferences for Simpler Theories
- Conclusion
- References and Further Reading
1. The Role of Simplicity in Science
There are many ways in which simplicity might be regarded as a desirable feature of scientific theories. Simpler theories are frequently said to be more “beautiful” or more “elegant” than their rivals; they might also be easier to understand and to work with. However, according to many scientists and philosophers, simplicity is not something that is merely to be hoped for in theories; nor is it something that we should only strive for after we have already selected a theory that we believe to be on the right track (for example, by trying to find a simpler formulation of an accepted theory). Rather, the claim is that simplicity should actually be one of the key criteria that we use to evaluate which of a set of rival theories is, in fact, the best theory, given the available evidence: other things being equal, the simplest theory consistent with the data is the best one.
This view has a long and illustrious history. Though it is now most commonly associated with the 14th century philosopher, William of Ockham (also spelt “Occam”), whose name is attached to the famous methodological maxim known as “Ockham’s razor”, which is often interpreted as enjoining us to prefer the simplest theory consistent with the available evidence, it can be traced at least as far back as Aristotle. In his Posterior Analytics, Aristotle argued that nothing in nature was done in vain and nothing was superfluous, so our theories of nature should be as simple as possible. Several centuries later, at the beginning of the modern scientific revolution, Galileo espoused a similar view, holding that, “[n]ature does not multiply things unnecessarily; that she makes use of the easiest and simplest means for producing her effects” (Galilei, 1962, p396). Similarly, at beginning of the third book of the Principia, Isaac Newton included the following principle among his “rules for the study of natural philosophy”:
- No more causes of natural things should be admitted than are both true and sufficient to explain their phenomena.
As the philosophers say: Nature does nothing in vain, and more causes are in vain when fewer will suffice. For Nature is simple and does not indulge in the luxury of superfluous causes. (Newton, 1999, p794 [emphasis in original]).
In the 20th century, Albert Einstein asserted that “our experience hitherto justifies us in believing that nature is the realisation of the simplest conceivable mathematical ideas” (Einstein, 1954, p274). More recently, the eminent physicist Steven Weinberg has claimed that he and his fellow physicists “demand simplicity and rigidity in our principles before we are willing to take them seriously” (Weinberg, 1993, p148-9), while the Nobel prize winning economist John Harsanyi has stated that “[o]ther things being equal, a simpler theory will be preferable to a less simple theory” (quoted in McAlleer, 2001, p296).
It should be noted, however, that not all scientists agree that simplicity should be regarded as a legitimate criterion for theory choice. The eminent biologist Francis Crick once complained, “[w]hile Occam’s razor is a useful tool in physics, it can be a very dangerous implement in biology. It is thus very rash to use simplicity and elegance as a guide in biological research” (Crick, 1988, p138). Similarly, here are a group of earth scientists writing in Science:
- Many scientists accept and apply [Ockham’s Razor] in their work, even though it is an entirely metaphysical assumption. There is scant empirical evidence that the world is actually simple or that simple accounts are more likely than complex ones to be true. Our commitment to simplicity is largely an inheritance of 17th-century theology. (Oreskes et al, 1994, endnote 25)
Hence, while very many scientists assert that rival theories should be evaluated on grounds of simplicity, others are much more skeptical about this idea. Much of this skepticism stems from the suspicion that the cogency of a simplicity criterion depends on assuming that nature is simple (hardly surprising given the way that many scientists have defended such a criterion) and that we have no good reason to make such an assumption. Crick, for instance, seemed to think that such an assumption could make no sense in biology, given the patent complexity of the biological world. In contrast, some advocates of simplicity have argued that a preference for simple theories need not necessarily assume a simple world—for instance, even if nature is demonstrably complex in an ontological sense, we should still prefer comparatively simple explanations for nature’s complexity. Oreskes and others also emphasize that the simplicity principles of scientists such as Galileo and Newton were explicitly rooted in a particular kind of natural theology, which held that a simple and elegant universe was a necessary consequence of God’s benevolence. Today, there is much less enthusiasm for grounding scientific methods in theology (the putative connection between God’s benevolence and the simplicity of creation is theologically controversial in any case). Another common source of skepticism is the apparent vagueness of the notion of simplicity and the suspicion that scientists’ judgments about the relative simplicity of theories lack a principled and objective basis.
Even so, there is no doubting the popularity of the idea that simplicity should be used as a criterion for theory choice and evaluation. It seems to be explicitly ingrained into many scientific methods—for instance, standard statistical methods of data analysis (Section 1d). It has also spread far beyond philosophy and the natural sciences. A recent issue of the FBI Law Enforcement Bulletin, for instance, contained the advice that “[u]nfortunately, many people perceive criminal acts as more complex than they really are… the least complicated explanation of an event is usually the correct one” (Rothwell, 2006, p24).
a. Ockham’s Razor
Many scientists and philosophers endorse a methodological principle known as “Ockham’s Razor”. This principle has been formulated in a variety of different ways. In the early 21st century, it is typically just equated with the general maxim that simpler theories are “better” than more complex ones, other things being equal. Historically, however, it has been more common to formulate Ockham’s Razor as a more specific type of simplicity principle, often referred to as “the principle of parsimony”. Whether William of Ockham himself would have endorsed any of the wide variety of methodological maxims that have been attributed to him is a matter of some controversy (see Thorburn, 1918; entry on William of Ockham), since Ockham never explicitly referred to a methodological principle that he called his “razor”. However, a standard of formulation of the principle of parsimony—one that seems to be reasonably close to the sort of principle that Ockham himself probably would have endorsed—is as the maxim “entities are not to be multiplied beyond necessity”. So stated, the principle is ontological, since it is concerned with parsimony with respect to the entities that theories posit the existence of in attempting to account for the empirical data. “Entity”, in this context, is typically understood broadly, referring not just to objects (for example, atoms and particles), but also to other kinds of natural phenomena that a theory may include in its ontology, such as causes, processes, properties, and so forth. Other, more general formulations of Ockham’s Razor are not exclusively ontological, and may also make reference to various structural features of how theories go about explaining nature, such as the unity of their explanations. The remainder of this section will focus on the more traditional ontological interpretation.
It is important to recognize that the principle, “entities are not to be multiplied beyond necessity” can be read in at least two different ways. One way of reading it is as what we can call an anti-superfluity principle (Barnes, 2000). This principle calls for the elimination of ontological posits from theories that are explanatorily redundant. Suppose, for instance, that there are two theories, T1 and T2, which both seek to explain the same set of empirical data, D. Suppose also that T1 and T2 are identical in terms of the entities that are posited, except for the fact that T2 entails an additional posit, b, that is not part of T1. So let us say that T1 posits a, while T2 posits a + b. Intuitively, T2 is a more complex theory than T1 because it posits more things. Now let us assume that both theories provide an equally complete explanation of D, in the sense that there are no features of D that the two theories cannot account for. In this situation, the anti-superfluity principle would instruct us to prefer the simpler theory, T1, to the more complex theory, T2. The reason for this is because T2 contains an explanatorily redundant posit, b, which does no explanatory work in the theory with respect to D. We know this because T1, which posits a alone provides an equally adequate account of D as T2. Hence, we can infer that positing a alone is sufficient to acquire all the explanatory ability offered by T2, with respect to D; adding b does nothing to improve the ability of T2 to account for the data.
This sort of anti-superfluity principle underlies one important interpretation of “entities are not to be multiplied beyond necessity”: as a principle that invites us to get rid of superfluous components of theories. Here, an ontological posit is superfluous with respect to a given theory, T, in so far as it does nothing to improve T’s ability to account for the phenomena to be explained. This is how John Stuart Mill understood Ockham’s razor (Mill, 1867, p526). Mill also pointed to a plausible justification for the anti-superfluity principle: explanatorily redundant posits—those that have no effect on the ability of the theory to explain the data—are also posits that do not obtain evidential support from the data. This is because it is plausible that theoretical entities are evidentially supported by empirical data only to the extent that they can help us to account for why the data take the form that they do. If a theoretical entity fails to contribute to this end, then the data fails to confirm the existence of this entity. If we have no other independent reason to postulate the existence of this entity, then we have no justification for including this entity in our theoretical ontology.
Another justification that has been offered for the anti-superfluity principle is a probabilistic one. Note that T2 is a logically stronger theory than T1: T2 says that a and b exist, while T1 says that only a exists. It is a consequence of the axioms of probability that a logically stronger theory is always less probable than a logically weaker theory, thus, so long as the probability of a existing and the probability of b existing are independent of each other, the probability of a existing is greater than zero, and the probability of b existing is less than 1, we can assert that Pr (a exists) > Pr (a exists & b exists), where Pr (a exists & b exists) = Pr (a exists) * Pr (b exists). According to this reasoning, we should therefore regard the claims of T1 as more a priori probable than the claims of T2, and this is a reason to prefer it. However, one objection to this probabilistic justification for the anti-superfluity principle is that it doesn’t fully explain why we dislike theories that posit explanatorily redundant entities: it can’t really because they are logically stronger theories; rather it is because they postulate entities that are unsupported by evidence.
When the principle of parsimony is read as an anti-superfluity principle, it seems relatively uncontroversial. However, it is important to recognize that the vast majority of instances where the principle of parsimony is applied (or has been seen as applying) in science cannot be given an interpretation merely in terms of the anti-superfluity principle. This is because the phrase “entities are not to be multiplied beyond necessity” is normally read as what we can call an anti-quantity principle: theories that posit fewer things are (other things being equal) to be preferred to theories that posit more things, whether or not the relevant posits play any genuine explanatory role in the theories concerned (Barnes, 2000). This is a much stronger claim than the claim that we should razor off explanatorily redundant entities. The evidential justification for the anti-superfluity principle just described cannot be used to motivate the anti-quantity principle, since the reasoning behind this justification allows that we can posit as many things as we like, so long as all of the individual posits do some explanatory work within the theory. It merely tells us to get rid of theoretical ontology that, from the perspective of a given theory, is explanatorily redundant. It does not tell us that theories that posit fewer things when accounting for the data are better than theories that posit more things—that is, that sparser ontologies are better than richer ones.
Another important point about the anti-superfluity principle is that it does not give us a reason to assert the non-existence of the superfluous posit. Absence of evidence, is not (by itself) evidence for absence. Hence, this version of Ockham’s razor is sometimes also referred to as an “agnostic” razor rather than an “atheistic” razor, since it only motivates us to be agnostic about the razored-off ontology (Sober, 1981). It seems that in most cases where Ockham’s razor is appealed to in science it is intended to support atheistic conclusions—the entities concerned are not merely cut out of our theoretical ontology, their existence is also denied. Hence, if we are to explain why such a preference is justified we need will to look for a different justification. With respect to the probabilistic justification for the anti-superfluity principle described above, it is important to note that it is not an axiom of probability that Pr (a exists & b doesn’t exist) > Pr (a exists & b exists).
b. Examples of Simplicity Preferences at Work in the History of Science
It is widely believed that there have been numerous episodes in the history of science where particular scientific theories were defended by particular scientists and/or came to be preferred by the wider scientific community less for directly empirical reasons (for example, some telling experimental finding) than as a result of their relative simplicity compared to rival theories. Hence, the history of science is taken to demonstrate the importance of simplicity considerations in how scientists defend, evaluate, and choose between theories. One striking example is Isaac Newton’s argument for universal gravitation.
i. Newton’s Argument for Universal Gravitation
At beginning of the third book of the Principia, subtitled “The system of the world”, Isaac Newton described four “rules for the study of natural philosophy”:
- Rule 1 No more causes of natural things should be admitted than are both true and sufficient to explain their phenomena.
- As the philosophers say: Nature does nothing in vain, and more causes are in vain when fewer will suffice. For Nature is simple and does not indulge in the luxury of superfluous causes.
- Rule 2 Therefore, the causes assigned to natural effects of the same kind must be, so far as possible, the same.
- Rule 3 Those qualities of bodies that cannot be intended and remitted [i.e., qualities that cannot be increased and diminished] and that belong to all bodies on which experiments can be made should be taken as qualities of all bodies universally.
- For the qualities of bodies can be known only through experiments; and therefore qualities that square with experiments universally are to be regarded as universal qualities… Certainly ideal fancies ought not to be fabricated recklessly against the evidence of experiments, nor should we depart from the analogy of nature, since nature is always simple and ever consonant with itself…
- Rule 4 In experimental philosophy, propositions gathered from phenomena by induction should be considered either exactly or very nearly true notwithstanding any contrary hypotheses, until yet other phenomena make such propositions either more exact or liable to exceptions.
- This rule should be followed so that arguments based on induction may not be nullified by hypotheses. (Newton, 1999, p794-796).
Here we see Newton explicitly placing simplicity at the heart of his conception of the scientific method. Rule 1, a version of Ockham’s Razor, which, despite the use of the word “superfluous”, has typically been read as an anti-quantity principle rather than an anti-superfluity principle (see Section 1a), is taken to follow directly from the assumption that nature is simple, which is in turn taken to give rise to rules 2 and 3, both principles of inductive generalization (infer similar causes for similar effects, and assume to be universal in all bodies those properties found in all observed bodies). These rules play a crucial role in what follows, the centrepiece being the argument for universal gravitation.
After laying out these rules of method, Newton described several “phenomena”—what are in fact empirical generalizations, derived from astronomical observations, about the motions of the planets and their satellites, including the moon. From these phenomena and the rules of method, he then “deduced” several general theoretical propositions. Propositions 1, 2, and 3 state that the satellites of Jupiter, the primary planets, and the moon are attracted towards the centers of Jupiter, the sun, and the earth respectively by forces that keep them in their orbits (stopping them from following a linear path in the direction of their motion at any one time). These forces are also claimed to vary inversely with the square of the distance of the orbiting body (for example, Mars) from the center of the body about which it orbits (for example, the sun). These propositions are taken to follow from the phenomena, including the fact that the respective orbits can be shown to (approximately) obey Kepler’s law of areas and the harmonic law, and the laws of motion developed in book 1 of the Principia. Newton then asserted proposition 4: “The moon gravitates toward the earth and by the force of gravity is always drawn back from rectilinear motion and kept in its orbit” (p802). In other words, it is the force of gravity that keeps the moon in its orbit around the earth. Newton explicitly invoked rules 1 and 2 in the argument for this proposition (what has become known as the “moon-test”). First, astronomical observations told us how fast the moon accelerates towards the earth. Newton was then able to calculate what the acceleration of the moon would be at the earth’s surface, if it were to fall down to the earth. This turned out to be equal to the acceleration of bodies observed to fall in experiments conducted on earth. Since it is the force of gravity that causes bodies on earth to fall (Newton assumed his readers’ familiarity with “gravity” in this sense), and since both gravity and the force acting on the moon “are directed towards the center of the earth and are similar to each other and equal”, Newton asserted that “they will (by rules 1 and 2) have the same cause” (p805). Therefore, the forces that act on falling bodies on earth, and which keeps the moon in its orbit are one and the same: gravity. Given this, the force of gravity acting on terrestrial bodies could now be claimed to obey an inverse-square law. Through similar deployment of rules 1, 2, and 4, Newton was led to the claim that it is also gravity that keeps the planets in their orbits around the sun and the satellites of Jupiter and Saturn in their orbits, since these forces are also directed toward the centers of the sun, Jupiter, and Saturn, and display similar properties to the force of gravity on earth, such as the fact that they obey an inverse-square law. Therefore, the force of gravity was held to act on all planets universally. Through several more steps, Newton was eventually able to get to the principle of universal gravitation: that gravity is a mutually attractive force that acts on any two bodies whatsoever and is described by an inverse-square law, which says that the each body attracts the other with a force of equal magnitude that is proportional to the product of the masses of the two bodies and inversely proportional to the squared distance between them. From there, Newton was able to determine the masses and densities of the sun, Jupiter, Saturn, and the earth, and offer a new explanation for the tides of the seas, thus showing the remarkable explanatory power of this new physics.
Newton’s argument has been the subject of much debate amongst historians and philosophers of science (for further discussion of the various controversies surrounding its structure and the accuracy of its premises, see Glymour, 1980; Cohen, 1999; Harper, 2002). However, one thing that seems to be clear is that his conclusions are by no means forced on us through simple deductions from the phenomena, even when combined with the mathematical theorems and general theory of motion outlined in book 1 of the Principia. No experiment or mathematical derivation from the phenomena demonstrated that it must be gravity that is the common cause of the falling of bodies on earth, the orbits of the moon, the planets and their satellites, much less that gravity is a mutually attractive force acting on all bodies whatsoever. Rather, Newton’s argument appears to boil down to the claim that if gravity did have the properties accorded to it by the principle of universal gravitation, it could provide a common causal explanation for all the phenomena, and his rules of method tell us to infer common causes wherever we can. Hence, the rules, which are in turn grounded in a preference for simplicity, play a crucial role in taking us from the phenomena to universal gravitation (for further discussion of the apparent link between simplicity and common cause reasoning, see Sober, 1988). Newton’s argument for universal gravitation can thus be seen as argument to the putatively simplest explanation for the empirical observations.
ii. Other Examples
Numerous other putative examples of simplicity considerations at work in the history of science have been cited in the literature:
- One of the most commonly cited concerns Copernicus’ arguments for the heliocentric theory of planetary motion. Copernicus placed particular emphasis on the comparative “simplicity” and “harmony” of the account that his theory gave of the motions of the planets compared with the rival geocentric theory derived from the work of Ptolemy. This argument appears to have carried significant weight for Copernicus’ successors, including Rheticus, Galileo, and Kepler, who all emphasized simplicity as a major motivation for heliocentrism. Philosophers have suggested various reconstructions of the Copernican argument (see for example, Glymour, 1980; Rosencrantz, 1983; Forster and Sober, 1994; Myrvold, 2003; Martens, 2009). However, historians of science have questioned the extent to which simplicity could have played a genuine rather than purely rhetorical role in this episode. For example, it has been argued that there is no clear sense in which the Copernican system was in fact simpler than Ptolemy’s, and that geocentric systems such as the Tychronic system could be constructed that were at least as simple as the Copernican one (for discussion, see Kuhn, 1957; Palter, 1970; Cohen, 1985; Gingerich, 1993; Martens, 2009).
- It has been widely claimed that simplicity played a key role in the development of Einstein’s theories of theories of special and general relativity, and in the early acceptance of Einstein’s theories by the scientific community (see for example, Hesse, 1974; Holton, 1974; Schaffner, 1974; Sober, 1981; Pais, 1982; Norton, 2000).
- Thagard (1988) argues that simplicity considerations played an important role in Lavoisier’s case against the existence of phlogiston and in favour of the oxygen theory of combustion.
- Carlson (1966) describes several episodes in the history of genetics in which simplicity considerations seemed to have held sway.
- Nolan (1997) argues that a preference for ontological parsimony played an important role in the discovery of the neutrino and in the proposal of Avogadro’s hypothesis.
- Baker (2007) argues that ontological parsimony was a key issue in discussions over rival dispersalist and extensionist bio-geographical theories in the late 19th and early 20th century.
Though it is commonplace for scientists and philosophers to claim that simplicity considerations have played a significant role in the history of science, it is important to note that some skeptics have argued that the actual historical importance of simplicity considerations has been over-sold (for example, Bunge, 1961; Lakatos and Zahar, 1978). Such skeptics dispute the claim that we can only explain the basis for these and other episodes of theory change by according a role to simplicity, claiming other considerations actually carried more weight. In addition, it has been argued that, in many cases, what appear on the surface to have been appeals to the relative simplicity of theories were in fact covert appeals to some other theoretical virtue (for example, Boyd, 1990; Sober, 1994; Norton, 2003; Fitzpatrick, 2009). Hence, for any putative example of simplicity at work in the history of science, it is important to consider whether the relevant arguments are not best reconstructed in other terms (such a “deflationary” view of simplicity will be discussed further in Section 4c).
c. Simplicity and Inductive Inference
Many philosophers have come to see simplicity considerations figuring not only in how scientists go about evaluating and choosing between developed scientific theories, but also in the mechanics of making much more basic inductive inferences from empirical data. The standard illustration of this in the modern literature is the practice of curve-fitting. Suppose that we have a series of observations of the values of a variable, y, given values of another variable, x. This gives us a series of data points, as represented in Figure 1.
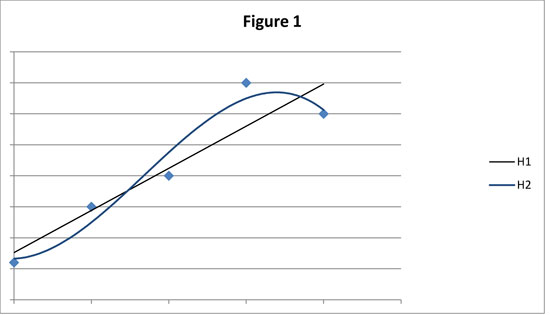
Given this data, what underlying relationship should we posit between x and y so that we can predict future pairs of x–y values? Standard practice is not to select a bumpy curve that neatly passes through all the data points, but rather to select a smooth curve—preferably a straight line, such as H1—that passes close to the data. But why do we do this? Part of an answer comes from the fact that if the data is to some degree contaminated with measurement error (for example, through mistakes in data collection) or “noise” produced by the effects of uncontrolled factors, then any curve that fits the data perfectly will most likely be false. However, this does not explain our preference for a curve like H1 over an infinite number of other curves—H2, for instance—that also pass close to the data. It is here that simplicity has been seen as playing a vital, though often implicit role in how we go about inferring hypotheses from empirical data: H1 posits a “simpler” relationship between x and y than H2—hence, it is for reasons of simplicity that we tend to infer hypotheses like H1.
The practice of curve-fitting has been taken to show that—whether we aware of it or not—human beings have a fundamental cognitive bias towards simple hypotheses. Whether we are deciding between rival scientific theories, or performing more basic generalizations from our experience, we ubiquitously tend to infer the simplest hypothesis consistent with our observations. Moreover, this bias is held to be necessary in order for us to be able select a unique hypotheses from the potentially limitless number of hypotheses consistent with any finite amount of experience.
The view that simplicity may often play an implicit role in empirical reasoning can arguably be traced back to David Hume’s description of enumerative induction in the context of his formulation of the famous problem of induction. Hume suggested that a tacit assumption of the uniformity of nature is ingrained into our psychology. Thus, we are naturally drawn to the conclusion that all ravens have black feathers from the fact that all previously observed ravens have black feathers because we tacitly assume that the world is broadly uniform in its properties. This has been seen as a kind of simplicity assumption: it is simpler to assume more of the same.
A fundamental link between simplicity and inductive reasoning has been retained in many more recent descriptive accounts of inductive inference. For instance, Hans Reichenbach (1949) described induction as an application of what he called the “Straight Rule”, modelling all inductive inference on curve-fitting. In addition, proponents of the model of “Inference to Best Explanation”, who hold that many inductive inferences are best understood as inferences to the hypothesis that would, if true, provide the best explanation for our observations, normally claim that simplicity is one of the criteria that we use to determine which hypothesis constitutes the “best” explanation.
In recent years, the putative role of simplicity in our inferential psychology has been attracting increasing attention from cognitive scientists. For instance, Lombrozo (2007) describes experiments that she claims show that participants use the relative simplicity of rival explanations (for instance, whether a particular medical diagnosis for a set of symptoms involves assuming the presence of one or multiple independent conditions) as a guide to assessing their probability, such that a disproportionate amount of contrary probabilistic evidence is required for participants to choose a more complex explanation over a simpler one. Simplicity considerations have also been seen as central to learning processes in many different cognitive domains, including language acquisition and category learning (for example, Chater, 1999; Lu and others, 2006).
d. Simplicity in Statistics and Data Analysis
Philosophers have long used the example of curve-fitting to illustrate the (often implicit) role played by considerations of simplicity in inductive reasoning from empirical data. However, partly due to the advent of low-cost computing power and that the fact scientists in many disciplines find themselves having to deal with ever larger and more intricate bodies of data, recent decades have seen a remarkable revolution in the methods available to scientists for analyzing and interpreting empirical data (Gauch, 2006). Importantly, there are now numerous formalized procedures for data analysis that can be implemented in computer software—and which are widely used in disciplines from engineering to crop science to sociology—that contain an explicit role for some notion of simplicity. The literature on such methods abounds with talk of “Ockham’s Razor”, “Occam factors”, “Ockham’s hill” (MacKay, 1992; Gauch, 2006), “Occam’s window” (Raftery and others, 1997), and so forth. This literature not only provides important illustrations of the role that simplicity plays in scientific practice, but may also offer insights for philosophers seeking to understand the basis for this role.
As an illustration, consider standard procedures for model selection, such as the Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), Minimum Message Length (MML) and Minimum Description Length (MDL) procedures, and numerous others (for discussion see, Forster and Sober, 1994; Forster, 2001; Gauch, 2003; Dowe and others, 2007). Model selection is a matter of selecting the kind of relationship that is to be posited between a set of variables, given a sample of data, in an effort to generate hypotheses about the true underlying relationship holding in the population of inference and/or to make predictions about future data. This question arises in the simple curve-fitting example discussed above—for instance, whether the true underlying relationship between x and y is linear, parabolic, quadratic, and so on. It also arises in lots of other contexts, such as the problem of inferring the causal relationship that exists between an empirical effect and a set of variables. “Models” in this sense are families of functions, such as the family of linear functions, LIN: y = a + bx, or the family of parabolic functions, PAR: y = a + bx + cx2. The simplicity of a model is normally explicated in terms of the number of adjustable parameters it contains (MML and MDL measure the simplicity of models in terms of the extent to which they provide compact descriptions of the data, but produce similar results to the counting of adjustable parameters). On this measure, the model LIN is simpler than PAR, since LIN contains two adjustable parameters, whereas PAR has three. A consequence of this is that a more complex model will always be able to fit a given sample of data better than a simpler model (“fitting” a model to the data involves using the data to determine what the values of the parameters in the model should be, given that data—that is, identifying the best-fitting member of the family). For instance, returning to the curve-fitting scenario represented in Figure 1, the best-fitting curve in PAR is guaranteed to fit this data set at least as well as the best-fitting member of the simpler model, LIN, and this is true no matter what the data are, since linear functions are special cases of parabolas, where c = 0, so any curve that is a member of LIN is also a member of PAR.
Model selection procedures produce a ranking of all the models under consideration in light of the data, thus allowing scientists to choose between them. Though they do it in different ways, AIC, BIC, MML, and MDL all implement procedures for model selection that impose a penalty on the complexity of a model, so that a more complex model will have to fit the data sample at hand significantly better than a simpler one for it to be rated higher than the simpler model. Often, this penalty is greater the smaller is the sample of data. Interestingly—and contrary to the assumptions of some philosophers—this seems to suggest that simplicity considerations do not only come into play as a tiebreaker between theories that fit the data equally well: according to the model selection literature, simplicity sometimes trumps better fit to the data. Hence, simplicity need not only come into play when all other things are equal.
Both statisticians and philosophers of statistics have vigorously debated the underlying justification for these sorts of model selection procedures (see, for example, the papers in Zellner and others, 2001). However, one motivation for taking into account the simplicity of models derives from a piece of practical wisdom: when there is error or “noise” in the data sample, a relatively simple model that fits the sample less well will often be more accurate when it comes to predicting extra-sample (for example, future) data than a more complex model that fits the sample more closely. The logic here is that since more complex models are more flexible in their ability to fit the data (since they have more adjustable parameters), they also have a greater propensity to be misled by errors and noise, in which case they may recover less of the true underlying “signal” in the sample. Thus, constraining model complexity may facilitate greater predictive accuracy. This idea is captured in what Gauch (2003, 2006) (following MacKay, 1992) calls “Ockham’s hill”. To the left of the peak of the hill, increasing the complexity of a model improves its accuracy with respect to extra-sample data because this recovers more of the signal in the sample. However, after the peak, increasing complexity actually diminishes predictive accuracy because this leads to over-fitting to spurious noise in the sample. There is therefore an optimal trade-off (at the peak of Ockham’s hill) between simplicity and fit to the sample data when it comes to facilitating accurate prediction of extra-sample data. Indeed, this trade-off is essentially the core idea behind AIC, the development of which initiated the now enormous literature on model selection, and the philosophers Malcolm Forster and Elliott Sober have sought to use such reasoning to make sense of the role of simplicity in many areas of science (see Section 4biii).
One important implication of this apparent link between model simplicity and predictive accuracy is that interpreting sample data using relatively simple models may improve the efficiency of experiments by allowing scientists to do more with less data—for example, scientists may be able to run a costly experiment fewer times before they can be in a position to make relatively accurate predictions about the future. Gauch (2003, 2006) describes several real world cases from crop science and elsewhere where this gain in accuracy and efficiency from the use of relatively simple models has been documented.
2. Wider Philosophical Significance of Issues Surrounding Simplicity
The putative role of simplicity, both in the evaluation of rival scientific theories and in the mechanics of how we go about inferring hypotheses from empirical data, clearly raises a number of difficult philosophical issues. These include, but are by no means limited to: (1) the question of what precisely it means to say the one theory or hypothesis is simpler than another and how the relative simplicity of theories is to be measured; (2) the question of what rational justification (if any) can be provided for choosing between rival theories on grounds of simplicity; and (3) the closely related question of what weight simplicity considerations ought to carry in theory choice relative to other theoretical virtues, particularly if these sometimes have to be traded-off against each other. (For general surveys of the philosophical literature on these issues, see Hesse, 1967; Sober, 2001a, 2001b). Before we delve more deeply into how philosophers have sought to answer these questions, it is worth noting the close connections between philosophical issues surrounding simplicity and many of the most important controversies in the philosophy of science and epistemology.
First, the problem of simplicity has close connections with long-standing issues surrounding the nature and justification of inductive inference. Some philosophers have actually offered up the idea that simpler theories are preferable to less simple ones as a purported solution to the problem of induction: it is the relative simplicity of the hypotheses that we tend to infer from empirical observations that supposedly provides the justification for these inferences—thus, it is simplicity that provides the warrant for our inductive practices. This approach is not as popular as it once was, since it is taken to merely substitute the problem of induction for the equally substantive problem of justifying preferences for simpler theories. A more common view in the recent literature is that the problem of induction and the problem of justifying preferences for simpler theories are closely connected, or may even amount to the same problem. Hence, a solution to the latter problem will provide substantial help towards solving the former.
More generally, the ability to make sense of the putative role of simplicity in scientific reasoning has been seen by many to be a central desideratum for any adequate philosophical theory of the scientific method. For example, Thomas Kuhn’s (1962) influential discussion of the importance of scientists’ aesthetic preferences—including but not limited to judgments of simplicity—in scientific revolutions was a central part of his case for adopting a richer conception of the scientific method and of theory change in science than he found in the dominant logical empiricist views of the time. More recently, critics of the Bayesian approach to scientific reasoning and theory confirmation, which holds that sound inductive reasoning is reasoning according to the formal principles of probability, have claimed that simplicity is an important feature of scientific reasoning that escapes a Bayesian analysis. For instance, Forster and Sober (1994) argue that Bayesian approaches to curve-fitting and model selection (such as the Bayesian Information Criterion) cannot themselves be given Bayesian rationale, nor can any other approach that builds in a bias towards simpler models. The ability of the Bayesian approach to make sense of simplicity in model selection and other aspects of scientific practice has thus been seen as central to evaluating its promise (see for example, Glymour, 1980; Forster and Sober, 1994; Forster, 1995; Kelly and Glymour, 2004; Howson and Urbach, 2006; Dowe and others, 2007).
Discussions over the legitimacy of simplicity as a criterion for theory choice have also been closely bound up with debates over scientific realism. Scientific realists assert that scientific theories aim to offer a literally true description of the world and that we have good reason to believe that the claims of our current best scientific theories are at least approximately true, including those claims that purport to be about “unobservable” natural phenomena that are beyond our direct perceptual access. Some anti-realists object that it is possible to formulate incompatible alternatives to our current best theories that are just as consistent with any current data that we have, perhaps even any future data that we could ever collect. They claim that we can therefore never be justified in asserting that the claims of our current best theories, especially those concerning unobservables, are true, or approximately true. A standard realist response is to emphasize the role of the so-called “theoretical virtues” in theory choice, among which simplicity is normally listed. The claim is thus that we rule out these alternative theories because they are unnecessarily complex. Importantly, for this defense to work, realists have to defend the idea that not only are we justified in choosing between rival theories on grounds of simplicity, but also that simplicity can be used as a guide to the truth. Naturally, anti-realists, particularly those of an empiricist persuasion (for example, van Fraassen, 1989), have expressed deep skepticism about the alleged truth-conduciveness of a simplicity criterion.
3. Defining and Measuring Simplicity
The first major philosophical problem that seems to arise from the notion that simplicity plays a role in theory choice and evaluation concerns specifying in more detail what it means to say that one theory is simpler than another and how the relative simplicity of theories is to be precisely and objectively measured. Numerous attempts have been made to formulate definitions and measures of theoretical simplicity, all of which face very significant challenges. Philosophers have not been the only ones to contribute to this endeavour. For instance, over the last few decades, a number of formal measures of simplicity and complexity have been developed in mathematical information theory. This section provides an overview of some of the main simplicity measures that have been proposed and the problems that they face. The proposals described here have also normally been tied to particular proposals about what justifies preferences for simpler theories. However, discussion of these justifications will be left until Section 4.
To begin with, it is worth considering why providing a precise definition and measure of theoretical simplicity ought to be regarded as a substantial philosophical problem. After all, it often seems that when one is confronted with a set of rival theories designed to explain a particular empirical phenomenon, it is just obvious which is the simplest. One does not always need a precise definition or measure of a particular property to be able to tell whether or not something exhibits it to a greater degree than something else. Hence, it could be suggested that if there is a philosophical problem here, it is only of very minor interest and certainly of little relevance to scientific practice. There are, however, some reasons to regard this as a substantial philosophical problem, which also has some practical relevance.
First, it is not always easy to tell whether one theory really ought to be regarded as simpler than another, and it is not uncommon for practicing scientists to disagree about the relative simplicity of rival theories. A well-known historical example is the disagreement between Galileo and Kepler concerning the relative simplicity of Copernicus’ theory of planetary motion, according to which the planets move only in perfect circular orbits with epicycles, and Kepler’s theory, according to which the planets move in elliptical orbits (see Holton, 1974; McAllister, 1996). Galileo held to the idea that perfect circular motion is simpler than elliptical motion. In contrast, Kepler emphasized that an elliptical model of planetary motion required many fewer orbits than a circular model and enabled a reduction of all the planetary motions to three fundamental laws of planetary motion. The problem here is that scientists seem to evaluate the simplicity of theories along a number of different dimensions that may conflict with each other. Hence, we have to deal with the fact that a theory may be regarded as simpler than a rival in one respect and more complex in another. To illustrate this further, consider the following list of commonly cited ways in which theories may be held to be simpler than others:
- Quantitative ontological parsimony (or economy): postulating a smaller number of independent entities, processes, causes, or events.
- Qualitative ontological parsimony (or economy): postulating a smaller number of independent kinds or classes of entities, processes, causes, or events.
- Common cause explanation: accounting for phenomena in terms of common rather than separate causal processes.
- Symmetry: postulating that equalities hold between interacting systems and that the laws describing the phenomena look the same from different perspectives.
- Uniformity (or homogeneity): postulating a smaller number of changes in a given phenomenon and holding that the relations between phenomena are invariant.
- Unification: explaining a wider and more diverse range of phenomena that might otherwise be thought to require separate explanations in a single theory (theoretical reduction is generally held to be a species of unification).
- Lower level processes: when the kinds of processes that can be posited to explain a phenomena come in a hierarchy, positing processes that come lower rather than higher in this hierarchy.
- Familiarity (or conservativeness): explaining new phenomena with minimal new theoretical machinery, reusing existing patterns of explanation.
- Paucity of auxiliary assumptions: invoking fewer extraneous assumptions about the world.
- Paucity of adjustable parameters: containing fewer independent parameters that the theory leaves to be determined by the data.
As can be seen from this list, there is considerable diversity here. We can see that theoretical simplicity is frequently thought of in ontological terms (for example, quantitative and qualitative parsimony), but also sometimes as a structural feature of theories (for example, unification, paucity of adjustable parameters), and while some of these intuitive types of simplicity may often cluster together in theories—for instance, qualitative parsimony would seem to often go together with invoking common cause explanations, which would in turn often seem to go together with explanatory unification—there is also considerable scope for them pointing in different directions in particular cases. For example, a theory that is qualitatively parsimonious as a result of positing fewer different kinds of entities might be quantitatively unparsimonious as result of positing more of a particular kind of entity; while the demand to explain in terms of lower-level processes rather than higher-level processes may conflict with the demand to explain in terms of common causes behind similar phenomena, and so on. There are also different possible ways of evaluating the simplicity of a theory with regard to any one of these intuitive types of simplicity. A theory may, for instance, come out as more quantitatively parsimonious than another if one focuses on the number of independent entities that it posits, but less parsimonious if one focuses on the number of independent causes it invokes. Consequently, it seems that if a simplicity criterion is actually to be applicable in practice, we need some way of resolving the disagreements that may arise between scientists about the relative simplicity of rival theories, and this requires a more precise measure of simplicity.
Second, as has already been mentioned, a considerable amount of the skepticism expressed both by philosophers and by scientists about the practice of choosing one theory over another on grounds of relative simplicity has stemmed from the suspicion that our simplicity judgments lack a principled basis (for example, Ackerman, 1961; Bunge, 1961; Priest, 1976). Disagreements between scientists, along with the multiplicity and scope for conflict between intuitive types of simplicity have been important contributors to this suspicion, leading to the view that for any two theories, T1 and T2, there is some way of evaluating their simplicity such that T1 comes out as simpler than T2, and vice versa. It seems, then, that an adequate defense of the legitimacy a simplicity criterion needs to show that there are in fact principled ways of determining when one theory is indeed simpler than another. Moreover, in so far as there is also a justificatory issue to be dealt with, we also need to be clear about exactly what it is that we need to justify a preference for.
a. Syntactic Measures
One proposal is that the simplicity of theories can be precisely and objectively measured in terms of how briefly they can be expressed. For example, a natural way of measuring the simplicity of an equation is just to count the number of terms, or parameters that it contains. Similarly, we could measure the simplicity of a theory in terms of the size of the vocabulary—for example, the number of extra-logical terms—required to write down its claims. Such measures of simplicity are often referred to as syntactic measures, since they involve counting the linguistic elements required to state, or to describe the theory.
A major problem facing any such syntactic measure of simplicity is the problem of language variance. A measure of simplicity is language variant if it delivers different results depending on the language that is used to represent the theories being compared. Suppose, for example, that we measure the simplicity of an equation by counting the number of non-logical terms that it contains. This will produce the result that r = a will come out as simpler than x2 + y2 = a2. However, this second equation is simply a transformation of the first into Cartesian co-ordinates, where r2 = x2 + y2, and is hence logically equivalent. The intuitive proposal for measuring simplicity in curve-fitting contexts, according to which hypotheses are said to be simpler if they contain fewer parameters, is also language variant in this sense. How many parameters a hypothesis contains depends on the co-ordinate scales that one uses. For any two non-identical functions, F and G, there is some way of transforming the co-ordinate scales such that we can turn F into a linear curve and G into a non-linear curve, and vice versa.
Nelson Goodman’s (1983) famous “new riddle of induction” allows us to formulate another example of the problem of language variance. Suppose all previously observed emeralds have been green. Now consider the following hypotheses about the color properties of the entire population of emeralds:
- H1: all emeralds are green
- H2: all emeralds first observed prior to time t are green and all emeralds first observed after time t are blue (where t is some future time)
Intuitively, H1 seems to be a simpler hypothesis than H2. To begin with, it can be stated with a smaller vocabulary. H1 also seems to postulate uniformity in the properties of emeralds, while H2 posits non-uniformity. For instance, H2 seems to assume that there is some link between the time at which an emerald is first observed and its properties. Thus it can be viewed as including an additional time parameter. But now consider Goodman’s invented predicates, “grue” and “bleen”. These have been defined in variety of different ways, but let us define them here as follows: an object is grue if it is first observed before time t and the object is green, or first observed after t and the object is blue; an object is bleen if it is first observed before time t and the object is blue, or first observed after the time t and the object is green. With these predicates, we can define a further property, “grolor”. Grue and bleen are grolors just as green and blue are colors. Now, because of the way that grolors are defined, color predicates like “green” and “blue” can also be defined in terms of grolor predicates: an object is green if first observed before time t and the object is grue, or first observed after time t and the object is bleen; an object is blue if first observed before time t and the object is bleen, or first observed after t and the object is grue. This means that statements that are expressed in terms of green and blue can also be expressed in terms of grue and bleen. So, we can rewrite H1 and H2 as follows:
- H1: all emeralds first observed prior to time t are grue and all emeralds first observed after time t are bleen (where t is some future time)
- H2: all emeralds are grue
Re-call that earlier we judged H1 to be simpler than H2. However, if we are retain that simplicity judgment, we cannot say that H1 is simpler than H2 because it can be stated with a smaller vocabulary; nor can we say that it H1 posits greater uniformity, and is hence simpler, because it does not contain a time parameter. This is because simplicity judgments based on such syntactic features can be reversed merely by switching the language used to represent the hypotheses from a color language to a grolor language.
Examples such as these have been taken to show two things. First, no syntactic measure of simplicity can suffice to produce a principled simplicity ordering, since all such measures will produce different results depending of the language of representation that is used. It is not enough just to stipulate that we should evaluate simplicity in one language rather than another, since that would not explain why simplicity should be measured in that way. In particular, we want to know that our chosen language is accurately tracking the objective language-independent simplicity of the theories being compared. Hence, if a syntactic measure of simplicity is to be used, say for practical purposes, it must be underwritten by a more fundamental theory of simplicity. Second, a plausible measure of simplicity cannot be entirely neutral with respect to all of the different claims about the world that the theory makes or can be interpreted as making. Because of the respective definitions of colors and grolors, any hypothesis that posits uniformity in color properties must posit non-uniformity in grolor properties. As Goodman emphasized, one can find uniformity anywhere if no restriction is placed on what kinds of properties should be taken into account. Similarly, it will not do to say that theories are simpler because they posit the existence of fewer entities, causes and processes, since, using Goodman-like manipulations, it is trivial to show that a theory can be regarded as positing any number of different entities, causes and processes. Hence, some principled restriction needs to be placed on which aspects of the content of a theory are to be taken into account and which are to be disregarded when measuring their relative simplicity.
b. Goodman’s Measure
According to Nelson Goodman, an important component of the problem of measuring the simplicity of scientific theories is the problem of measuring the degree of systematization that a theory imposes on the world, since, for Goodman, to seek simplicity is to seek a system. In a series of papers in the 1940s and 50s, Goodman (1943, 1955, 1958, 1959) attempted to explicate a precise measure of theoretical systematization in terms of the logical properties of the set of concepts, or extra-logical terms, that make up the statements of the theory.
According to Goodman, scientific theories can be regarded as sets of statements. These statements contain various extra-logical terms, including property terms, relation terms, and so on. These terms can all be assigned predicate symbols. Hence, all the statements of a theory can be expressed in a first order language, using standard symbolic notion. For instance, “… is acid” may become “A(x)”, “… is smaller than ____” may become “S(x, y)”, and so on. Goodman then claims that we can measure the simplicity of the system of predicates employed by the theory in terms of their logical properties, such as their arity, reflexivity, transitivity, symmetry, and so on. The details arehighly technical but, very roughly, Goodman’s proposal is that a system of predicates that can be used to express more is more complex than a system of predicates that can be used to express less. For instance, one of the axioms of Goodman’s proposal is that if every set of predicates of a relevant kind, K, is always replaceable by a set of predicates of another kind, L, then K is not more complex than L.
Part of Goodman’s project was to avoid the problem of language variance. Goodman’s measure is a linguistic measure, since it concerns measuring the simplicity of a theory’s predicate basis in a first order language. However, it is not a purely syntactic measure, since it does not involve merely counting linguistic elements, such as the number of extra-logical predicates. Rather, it can be regarded as an attempt to measure the richness of a conceptual scheme: conceptual schemes that can be used to say more are more complex than conceptual schemes that can be used to say less. Hence, a theory can be regarded as simpler if it requires a less expressive system of concepts.
Goodman developed his axiomatic measure of simplicity in considerable detail. However, Goodman himself only ever regarded it as a measure of one particular type of simplicity, since it only concerns the logical properties of the predicates employed by the theory. It does not, for example, take account of the number of entities that a theory postulates. Moreover, Goodman never showed how the measure could be applied to real scientific theories. It has been objected that even if Goodman’s measure could be applied, it would not discriminate between many theories that intuitively differ in simplicity—indeed, in the kind of simplicity as systematization that Goodman wants to measure. For instance, it is plausible that the system of concepts used to express the Copernican theory of planetary motion is just as expressively rich as the system of concepts used to express the Ptolemaic theory, yet the former is widely regarded as considerably simpler than the latter, partly in virtue of it providing an intuitively more systematic account of the data (for discussion of the details of Goodman’s proposal and the objections it faces, see Kemeny, 1955; Suppes, 1956; Kyburg, 1961; Hesse, 1967).
c. Simplicity as Testability
It has often been argued that simpler theories say more about the world and hence are easier to test than more complex ones. C. S. Peirce (1931), for example, claimed that the simplest theories are those whose empirical consequences are most readily deduced and compared with observation, so that they can be eliminated more easily if they are wrong. Complex theories, on the other hand, tend to be less precise and allow for more wriggle room in accommodating the data. This apparent connection between simplicity and testability has led some philosophers to attempt to formulate measures of simplicity in terms of the relative testability of theories.
Karl Popper (1959) famously proposed one such testability measure of simplicity. Popper associated simplicity with empirical content: simpler theories say more about the world than more complex theories and, in so doing, place more restriction on the ways that the world can be. According to Popper, the empirical content of theories, and hence their simplicity, can be measured in terms of their falsifiability. The falsifiability of a theory concerns the ease with which the theory can be proven false, if the theory is indeed false. Popper argued that this could be measured in terms of the amount of data that one would need to falsify the theory. For example, on Popper’s measure, the hypothesis that x and y are linearly related, according to an equation of the form, y = a + bx, comes out as having greater empirical content and hence greater simplicity than the hypotheses that they are related according a parabola of the form, y = a + bx + cx2. This is because one only needs three data points to falsify the linear hypothesis, but one needs at least four data points to falsify the parabolic hypothesis. Thus Popper argued that empirical content, falsifiability, and hence simplicity, could be seen as equivalent to the paucity of adjustable parameters. John Kemeny (1955) proposed a similar testability measure, according to which theories are more complex if they can come out as true in more ways in an n-member universe, where n is the number of individuals that the universe contains.
Popper’s equation of simplicity with falsifiability suffers from some serious objections. First, it cannot be applied to comparisons between theories that make equally precise claims, such as a comparison between a specific parabolic hypothesis and a specific linear hypothesis, both of which specify precise values for their parameters and can be falsified by only one data point. It also cannot be applied when we compare theories that make probabilistic claims about the world, since probabilistic statements are not strictly falsifiable. This is particularly troublesome when it comes to accounting for the role of simplicity in the practice of curve-fitting, since one normally has to deal with the possibility of error in the data. As a result, an error distribution is normally added to the hypotheses under consideration, so that they are understood as conferring certain probabilities on the data, rather than as having deductive observational consequences. In addition, most philosophers of science now tend to think that falsifiability is not really an intrinsic property of theories themselves, but rather a feature of how scientists are disposed to behave towards their theories. Even deterministic theories normally do not entail particular observational consequences unless they are conjoined with particular auxiliary assumptions, usually leaving the scientist the option of saving the theory from refutation by tinkering with their auxiliary assumptions—a point famously emphasized by Pierre Duhem (1954). This makes it extremely difficult to maintain that simpler theories are intrinsically more falsifiable than less simple ones. Goodman (1961, p150-151) also argued that equating simplicity with falsifiability leads to counter-intuitive consequences. The hypothesis, “All maple trees are deciduous”, is intuitively simpler than the hypothesis, “All maple trees whatsoever, and all sassafras trees in Eagleville, are deciduous”, yet, according to Goodman, the latter hypothesis is clearly the easiest to falsify of the two. Kemeny’s measure inherits many of the same objections.
Both Popper and Kemeny essentially tried to link the simplicity of a theory with the degree to which it can accommodate potential future data: simpler theories are less accommodating than more complex ones. One interesting recent attempt to make sense of this notion of accommodation is due to Harman and Kulkarni (2007). Harman and Kulkarni analyze accommodation in terms of a concept drawn from statistical learning theory known as the Vapnik-Chervonenkis (VC) dimension. The VC dimension of a hypothesis can be roughly understood as a measure of the “richness” of the class of hypotheses from which it is drawn, where a class is richer if it is harder to find data that is inconsistent with some member of the class. Thus, a hypothesis drawn from a class that can fit any possible set of data will have infinite VC dimension. Though VC dimension shares some important similarities with Popper’s measure, there are important differences. Unlike Popper’s measure, it implies that accommodation is not always equivalent to the number of adjustable parameters. If we count adjustable parameters, sine curves of the form y = a sin bx, come out as relatively unaccommodating, however, such curves have an infinite VC dimension. While Harman and Kulkarni do not propose that VC dimension be taken as a general measure of simplicity (in fact, they regard it as an alternative to simplicity in some scientific contexts), ideas along these lines might perhaps hold some future promise for testability/accommodation measures of simplicity. Similar notions of accommodation in terms of “dimension” have been used to explicate the notion of the simplicity of a statistical model in the face of the fact the number of adjustable parameters a model contains is language variant (for discussion, see Forster, 1999; Sober, 2007).
d. Sober’s Measure
In his early work on simplicity, Elliott Sober (1975) proposed that the simplicity of theories be measured in terms of their question-relative informativeness. According to Sober, a theory is more informative if it requires less supplementary information from us in order for us to be able to use it to determine the answer to the particular questions that we are interested in. For instance, the hypothesis, y = 4x, is more informative and hence simpler than y = 2z + 2x with respect to the question, “what is the value of y?” This is because in order to find out the value of y one only needs to determine a value for x on the first hypothesis, whereas on the second hypothesis one also needs to determine a value for z. Similarly, Sober’s proposal can be used to capture the intuition that theories that say that a given class of things are uniform in their properties are simpler than theories that say that the class is non-uniform, because they are more informative relative to particular questions about the properties of the class. For instance, the hypothesis that “all ravens are black” is more informative and hence simpler than “70% of ravens are black” with respect to the question, “what will be the colour of the next observed raven?” This is because on the former hypothesis one needs no additional information in order to answer this question, whereas one will have to supplement the latter hypothesis with considerable extra information in order to generate a determinate answer.
By relativizing the notion of the content-fullness of theories to the question that one is interested in, Sober’s measure avoids the problem that Popper and Kemeny’s proposals faced of the most arbitrarily specific theories, or theories made up of strings of irrelevant conjunctions of claims, turning out to be the simplest. Moreover, according to Sober’s proposal, the content of the theory must be relevant to answering the question for it to count towards the theory’s simplicity. This gives rise to the most distinctive element of Sober’s proposal: different simplicity orderings of theories will be produced depending on the question one asks. For instance, if we want to know what the relationship is between values of z and given values of y and x, then y = 2z + 2x will be more informative, and hence simpler, than y = 4x. Thus, a theory can be simple relative to some questions and complex relative to others.
Critics have argued that Sober’s measure produces a number of counter-intuitive results. Firstly, the measure cannot explain why people tend to judge an equation such as y = 3x + 4x2 – 50 as more complex than an equation like y = 2x, relative to the question, “what is the value of y?” In both cases, one only needs a value of x to work out a value for y. Similarly, Sober’s measure fails to deal with Goodman’s above cited counter-example to the idea that simplicity equates to testability, since it produces the counter-intuitive outcome that there is no difference in simplicity between “all maple trees whatsoever, and all sassafras trees in Eagleville, are deciduous” and “all maple trees are deciduous” relative to questions about whether maple trees are deciduous. The interest-relativity of Sober’s measure has also generated criticism from those who prefer to see simplicity as a property that varies only with what a given theory is being compared with, not with the question that one happens to be asking.
e. Thagard’s Measure
Paul Thagard (1988) proposed that simplicity ought to be understood as a ratio of the number of facts explained by a theory to the number of auxiliary assumptions that the theory requires. Thagard defines an auxiliary assumption as a statement, not part of the original theory, which is assumed in order for the theory to be able to explain one or more of the facts to be explained. Simplicity is then measured as follows:
- Simplicity of T = (Facts explained by T – Auxiliary assumptions of T) / Facts explained by T
A value of 0 is given to a maximally complex theory that requires as many auxiliary assumptions as facts that it explains and 1 to a maximally simple theory that requires no auxiliary assumptions at all to explain. Thus, the higher the ratio of facts explained to auxiliary assumptions, the simpler the theory. The essence of Thagard’s proposal is that we want to explain as much as we can, while making the fewest assumptions about the way the world is. By balancing the paucity of auxiliary assumptions against explanatory power it prevents the unfortunate consequence of the simplest theories turning out to be those that are most anaemic.
A significant difficulty facing Thargard’s proposal lies in determining what the auxiliary assumptions of theories actually are and how to count them. It could be argued that the problem of counting auxiliary assumptions threatens to become as difficult as the original problem of measuring simplicity. What a theory must assume about the world for it to explain the evidence is frequently extremely unclear and even harder to quantify. In addition, some auxiliary assumptions are bigger and more onerous than others and it is not clear that they should be given equal weighting, as they are in Thagard’s measure. Another objection is that Thagard’s proposal struggles to make sense of things like ontological parsimony—the idea that theories are simpler because they posit fewer things—since it is not clear that parsimony per se would make any particular difference to the number of auxiliary assumptions required. In defense of this, Thagard has argued that ontological parsimony is actually less important to practicing scientists than has often been thought.
f. Information-Theoretic Measures
Over the last few decades, a number of formal measures of simplicity and complexity have been developed in mathematical information theory. Though many of these measures have been designed for addressing specific practical problems, the central ideas behind them have been claimed to have significance for addressing the philosophical problem of measuring the simplicity of scientific theories.
One of the prominent information-theoretic measures of simplicity in the current literature is Kolmogorov complexity, which is a formal measure of quantitative information content (see Li and Vitányi, 1997). The Kolmogorov complexity K(x) of an object x is the length in bits of the shortest binary program that can output a completely faithful description of x in some universal programming language, such as Java, C++, or LISP. This measure was originally formulated to measure randomness in data strings (such as sequences of numbers), and is based on the insight that non-random data strings can be “compressed” by finding the patterns that exist in them. If there are patterns in a data string, it is possible to provide a completely accurate description of it that is shorter than the string itself, in terms of the number of “bits” of information used in the description, by using the pattern as a mnemonic that eliminates redundant information that need not be encoded in the description. For instance, if the data string is an ordered sequence of 1s and 0s, where every 1 is followed by a 0, and every 0 by a 1, then it can be given a very short description that specifies the pattern, the value of the first data point and the number of data points. Any further information is redundant. Completely random data sets, however, contain no patterns, no redundancy, and hence are not compressible.
It has been argued that Kolmogorov complexity can be applied as a general measure of the simplicity of scientific theories. Theories can be thought of as specifying the patterns that exist in the data sets they are meant to explain. As a result, we can also think of theories as compressing the data. Accordingly, the more a theory T compresses the data, the lower the value of K for the data using T, and the greater is its simplicity. An important feature of Kolmogorov complexity is that it is measured in a universal programming language and it can be shown that the difference in code length between the shortest code length for x in one universal programming language and the shortest code length for x in another programming language is no more than a constant c, which depends on the languages chosen, rather than x. This has been thought to provide some handle on the problem of language variance: Kolmogorov complexity can be seen as a measure of “objective” or “inherent” information content up to an additive constant. Due to this, some enthusiasts have gone so far as to claim that Kolmogorov complexity solves the problem of defining and measuring simplicity.
A number of objections have been raised against this application of Kolmogorov complexity. First, finding K(x) is a non-computable problem: no algorithm exists to compute it. This is claimed to be a serious practical limitation of the measure. Another objection is that Kolmogorov complexity produces some counter-intuitive results. For instance, theories that make probabilistic rather than deterministic predictions about the data must have maximum Kolmogorov complexity. For example, a theory that says that a sequence of coin flips conforms to the probabilistic law, Pr(Heads) = ½, cannot be said to compress the data, since one cannot use this law to reconstruct the exact sequence of heads and tails, even though it offers an intuitively simple explanation of what we observe.
Other information-theoretic measures of simplicity, such as the Minimum Message Length (MML) and Minimum Description Length (MDL) measures, avoid some of the practical problems facing Kolmogorov complexity. Though there are important differences in the details of these measures (see Wallace and Dowe, 1999), they all adopt the same basic idea that the simplicity of an empirical hypothesis can be measured in terms of the extent to which it provides a compact encoding of the data.
A general objection to all such measures of simplicity is that scientific theories generally aim to do more than specify patterns in the data. They also aim to explain why these patterns are there and it is in relation to how theories go about explaining the patterns in our observations that theories have often been thought to be simple or complex. Hence, it can be argued that mere data compression cannot, by itself, suffice as an explication of simplicity in relation to scientific theories. A further objection to the data compression approach is that theories can be viewed as compressing data sets in a very large number of different ways, many of which we do not consider appropriate contributions to simplicity. The problem raised by Goodman’s new riddle of induction can be seen as the problem of deciding which regularities to measure: for example, color regularities or grolor regularities? Formal information-theoretic measures do not discriminate between different kinds of pattern finding. Hence, any such measure can only be applied once we specify the sorts of patterns and regularities that should be taken into account.
g. Is Simplicity a Unified Concept?
There is a general consensus in the philosophical literature that the project of articulating a precise general measure of theoretical simplicity faces very significant challenges. Of course, this has not stopped practicing scientists from utilizing notions of simplicity in their work, and particular concepts of simplicity—such as the simplicity of a statistical model, understood in terms of paucity of adjustable parameters or model dimension—are firmly entrenched in several areas of science. Given this, one potential way of responding to the difficulties that philosophers and others have encountered in this area—particularly in light of the apparent multiplicity and scope for conflict between intuitive explications of simplicity—is to raise the question of whether theoretical simplicity is in fact a unified concept at all. Perhaps there is no single notion of simplicity that is (or should be) employed by scientists, but rather a cluster of different, sometimes related, but also sometimes conflicting notions of simplicity that scientists find useful to varying degrees in particular contexts. This might be evidenced by the observation that scientists’ simplicity judgments often involve making trade-offs between different notions of simplicity. Kepler’s preference for an astronomical theory that abandoned perfectly circular motions for the planets, but which could offer a unified explanation of the astronomical observations in terms of three basic laws, over a theory that retained perfect circular motion, but could not offer a similarly unified explanation, seems to be a clear example of this.
As a result of thoughts in this sort of direction, some philosophers have argued that there is actually no single theoretical value here at all, but rather a cluster of them (for example, Bunge, 1961). It is also worth considering the possibility that which of the cluster is accorded greater weight than the others, and how each of them is understood in practice, may vary greatly across different disciplines and fields of inquiry. Thus, what really matters when it comes to evaluating the comparative “simplicity” of theories might be quite different for biologists than for physicists, for instance, and perhaps what matters to a particle physicist is different to what matters to an astrophysicist. If there is in fact no unified concept of simplicity at work in science that might also indicate that there is no unitary justification for choosing between rival theories on grounds of simplicity. One important suggestion that this possibility has lead to is that the role of simplicity in science cannot be understood from a global perspective, but can only be understood locally. How simplicity ought to be measured and why it matters may have a peculiarly domain-specific explanation.
4. Justifying Preferences for Simpler Theories
Due to the apparent centrality of simplicity considerations to scientific methods and the link between it and numerous other important philosophical issues, the problem of justifying preferences for simpler theories is regarded as a major problem in the philosophy of science. It is also regarded as one of the most intractable. Though an extremely wide variety of justifications have been proposed—as with the debate over how to correctly define and measure simplicity, some important recent contributions have their origins in scientific literature in statistics, information theory, and other cognate fields—all of them have met with significant objections. There is currently no agreement amongst philosophers on what is the most promising path to take. There is also skepticism in some circles about whether an adequate justification is even possible.
Broadly speaking, justificatory proposals can be categorized into three types: 1) accounts that seek to show that simplicity is an indicator of truth (that is, that simpler theories are, in general, more likely to be true, or are somehow better confirmed by the empirical data than their more complex rivals); 2) accounts that do not regard simplicity as a direct indicator of truth, but which seek to highlight some alternative methodological justification for preferring simpler theories; 3) deflationary approaches, which actually reject the idea that there is a general justification for preferring simpler theories per se, but which seek to analyze particular appeals to simplicity in science in terms of other, less problematic, theoretical virtues.
a. Simplicity as an Indicator of Truth
i. Nature is Simple
Historically, the dominant view about why we should prefer simpler theories to more complex ones has been based on a general metaphysical thesis of the simplicity of nature. Since nature itself is simple, the relative simplicity of theories can thus be regarded as direct evidence for their truth. Such a view was explicitly endorsed by many of the great scientists of the past, including Aristotle, Copernicus, Galileo, Kepler, Newton, Maxwell, and Einstein. Naturally however, the question arises as to what justifies the thesis that nature is simple? Broadly speaking, there have been two different sorts of argument given for this thesis: i) that a benevolent God must have created a simple and elegant universe; ii) that the past record of success of relatively simple theories entitles us to infer that nature is simple. The theological justification was most common amongst scientists and philosophers during the early modern period. Einstein, on the other hand, invoked a meta-inductive justification, claiming that the history of physics justifies us in believing that nature is the realization of the simplest conceivable mathematical ideas.
Despite the historical popularity and influence of this view, more recent philosophers and scientists have been extremely resistant to the idea that we are justified in believing that nature is simple. For a start, it seems difficult to formulate the thesis that nature is simple so that it is not either obviously false, or too vague to be of any use. There would seem to be many counter-examples to the claim that we live in a simple universe. Consider, for instance, the picture of the atomic nucleus that physicists were working with in the early part of the twentieth century: it was assumed that matter was made only of protons and electrons; there were no such things as neutrons or neutrinos and no weak or strong nuclear forces to be explained, only electromagnetism. Subsequent discoveries have arguably led to a much more complex picture of nature and much more complex theories have had to be developed to account for this. In response, it could be claimed that though nature seems to be complex in some superficial respects, there is in fact a deep underlying simplicity in the fundamental structure of nature. It might also be claimed that the respects in which nature appears to be complex are necessary consequences of its underlying simplicity. But this just serves to highlight the vagueness of the claim that nature is simple—what exactly does this thesis amount to, and what kind of evidence could we have for it?
However the thesis is formulated, it would seem to be an extremely difficult one to adequately defend, whether this be on theological or meta-inductive grounds. An attempt to give a theological justification for the claim that nature is simple suffers from an inherent unattractiveness to modern philosophers and scientists who do not want to ground the legitimacy of scientific methods in theology. In any case, many theologians reject the supposed link between God’s benevolence and the simplicity of creation. With respect to a meta-inductive justification, even if it were the case that the history of science demonstrates the better than average success of simpler theories, we may still raise significant worries about the extent to which this could give sufficient credence to the claim that nature is simple. First, it assumes that empirical success can be taken to be a reliable indicator of truth (or at least approximate truth), and hence of what nature is really like. Though this is a standard assumption for many scientific realists—the claim being that success would be “miraculous” if the theory concerned was radically false—it is a highly contentious one, since many anti-realists hold that the history of science shows that all theories, even eminently successful theories, typically turn out to be radically false. Even if one does accept a link between success and truth, our successes to date may still not provide a representative sample of nature: maybe we have only looked at the problems that are most amenable to simple solutions and the real underlying complexity of nature has escaped our notice. We can also question the degree to which we can extrapolate any putative connection between simplicity and truth in one area of nature to nature as a whole. Moreover, in so far as simplicity considerations are held to be fundamental to inductive inference quite generally, such an attempted justification risks a charge of circularity.
ii. Meta-Inductive Proposals
There is another way of appealing to past success in order to try to justify a link between simplicity and truth. Instead of trying to justify a completely general claim about the simplicity of nature, this proposal merely suggests that we can infer a correlation between success and very particular simplicity characteristics in particular fields of inquiry—for instance, a particular kind of symmetry in certain areas of theoretical physics. If success can be regarded as an indicator of at least approximate truth, we can then infer that theories that are simpler in the relevant sense are more likely to be true in fields where the correlation with success holds.
Recent examples of this sort of proposal include McAllister (1996) and Kuipers (2002). In an effort to account for the truth-conduciveness of aesthetic considerations in science, including simplicity, Theo Kuipers (2002) claims that scientists tend to become attracted to theories that share particular aesthetic features in common with successful theories that they have been previously exposed to. In other words, we can explain the particular aesthetic preferences that scientists have in terms that are similar to a well-documented psychological effect known as the “mere-exposure effect”, which occurs when individuals take a liking to something after repeated exposure to it. If, in a given field of inquiry, theories that have been especially successful exhibit a particular type of simplicity (however this is understood), and thus such theories have been repeatedly presented to scientists working in the field during their training, the mere-exposure effect will then lead these scientists to be attracted to other theories that also exhibit that same type of simplicity. This process can then be used to support an aesthetic induction to a correlation between simplicity in the relevant sense and success. One can then make a case that this type of simplicity can legitimately be taken as an indicator of at least approximate truth.
Even though this sort of meta-inductive proposal does not attempt to show that nature in general is simple, many of the same objections can be raised against it as are raised against the attempt to justify that metaphysical thesis by appeal to the past success of simple theories. Once again, there is the problem of justifying the claim that empirical success is a reliable guide to (approximate) truth. Kuipers’ own arguments for this claim rest on a somewhat idiosyncratic account of truth approximation. In addition, in order to legitimately infer that there is a genuine correlation between simplicity and success, one cannot just look at successful theories; one must look at unsuccessful theories too. Even if all the successful theories in a domain have the relevant simplicity characteristic, it might still be the case that the majority of theories with the characteristic have been (or would have been) highly unsuccessful. Indeed, if one can potentially modify a successful theory in an infinite number of ways while keeping the relevant simplicity characteristic, one might actually be able to guarantee that the majority of possible theories with the characteristic would be unsuccessful theories, thus breaking the correlation between simplicity and success. This could be taken as suggesting that in order to carry any weight, arguments from success also need to offer an explanation for why simplicity contributes to success. Moreover, though the mere-exposure effect is well documented, Kuipers provides no direct empirical evidence that scientists actually acquire their aesthetic preferences via the kind of process that he proposes.
iii. Bayesian Proposals
According to standard varieties of Bayesianism, we should evaluate scientific theories according to their probability conditional upon the evidence (posterior probability). This probability, Pr(T | E), is a function of three quantities:
- Pr(T | E) = Pr(E | T) Pr(T) / Pr(E)
Pr(E | T), is the probability that the theory, T, confers on the evidence, E, which is referred to as the likelihood of T. Pr(T) is the prior probability of T, and Pr(E) is the probability of E. T is then held to have higher posterior probability than a rival theory, T*, if and only if:
- Pr(E | T) Pr(T) > Pr(E | T*) Pr(T*)
A standard Bayesian proposal for understanding the role of simplicity in theory choice is that simplicity is one of the key determinates of Pr(T): other things being equal, simpler theories and hypotheses are held to have higher prior probability of being true than more complex ones. Thus, if two rival theories confer equal or near equal probability on the data, but differ in relative simplicity, other things being equal, the simpler theory will tend to have a higher posterior probability. This idea, which Harold Jeffreys called “the simplicity postulate”, has been elaborated in a number of different ways by philosophers, statisticians, and information theorists, utilizing various measures of simplicity (for example, Carnap, 1950; Jeffreys, 1957, 1961; Solomonoff, 1964; Li, M. and Vitányi, 1997).
In response to this proposal, Karl Popper (1959) argued that, in some cases, assigning a simpler theory a higher prior probability actually violates the axioms of probability. For instance, Jeffreys proposed that simplicity be measured by counting adjustable parameters. On this measure, the claim that the planets move in circular orbits is simpler than the claim that the planets move in elliptical orbits, since the equation for an ellipse contains an additional adjustable parameter. However, circles can also be viewed as special cases of ellipses, where the additional parameter is set to zero. Hence, the claim that planets move in circular orbits can also be seen as a special case of the claim that the planets move in elliptical orbits. If that is right, then the former claim cannot be more probable than the latter claim because the truth of the former entails the truth of latter and probability respects entailment. In reply to Popper, it has been argued that this prior probabilistic bias towards simpler theories should only be seen as applying to comparisons between inconsistent theories where no relation of entailment holds between them—for instance, between the claim that the planets move in circular orbits and the claim that they move in elliptical but non-circular orbits.
The main objection to the Bayesian proposal that simplicity is a determinate of prior probability is that the theory of probability seems to offer no resources for explaining why simpler theories should be accorded higher prior probability. Rudolf Carnap (1950) thought that prior probabilities could be assigned a priori to any hypothesis stated in a formal language, on the basis of a logical analysis of the structure of the language and assumptions about the equi-probability of all possible states of affairs. However, Carnap’s approach has generally been recognized to be unworkable. If higher prior probabilities cannot be assigned to simpler theories on the basis of purely logical or mathematical considerations, then it seems that Bayesians must look outside of the Bayesian framework itself to justify the simplicity postulate.
Some Bayesians have taken an alternative route, claiming that a direct mathematical connection can be established between the simplicity of theories and their likelihood—that is, the value of Pr(E | T) ( see Rosencrantz, 1983; Myrvold, 2003; White, 2005). This proposal depends on the assumption that simpler theories have fewer adjustable parameters, and hence are consistent with a narrower range of potential data. Suppose that we collect a set of empirical data, E, that can be explained by two theories that differ with respect to this kind of simplicity: a simple theory, S, and a complex theory, C. S has no adjustable parameters and only ever entails E, while C has an adjustable parameter, θ, which can take a range of values, n. When θ is set to some specific value, i, it entails E, but on other values of θ, C entails different and incompatible observations. It is then argued that S confers a higher probability on E. This is because C allows that lots of other possible observations could have been made instead of E (on different possible settings for θ). Hence, the truth of C would make our recording those particular observations less probable than would the truth of S. Here, the likelihood of C is calculated as the average of the likelihoods of each of the n versions of C, defined by a unique setting of θ. Thus, as the complexity of a theory increases—measured in terms of the number of adjustable parameters it contains—the number of versions of the theory that will give a low probability to E will increase and the overall value of Pr(E | T) will go down.
An objection to this proposal (Kelly, 2004, 2010) is that for us to be able to show that S has a higher posterior probability than C as a result of its having a higher likelihood, it must be assumed that the prior probability of C is not significantly greater than the prior probability of S. This is a substantive assumption to make because of the way that simplicity is defined in this argument. We can view C as coming in a variety of different versions, each of which is picked out by a different value given to θ. If we then assume that S and C have roughly equal prior probability we must, by implication, assume that each version of C has a very low prior probability compared to S, since the prior probability of each version of C would be Pr(C) / n (assuming that the theory does not say that any particular parameter setting is more probable than any of the others). This would effectively build in a very strong prior bias in favour of S over each version of C. Given that each version of C could be considered independently—that is, the complex theory could be given a simpler, more restricted formulation—this would require an additional supporting argument. The objection is thus that the proposal simply begs the question by resting on a prior probabilistic bias towards simpler theories. Another objection is that the proposal suffers from the limitation that it can only be applied to comparisons between theories where the simpler theory can be derived from the more complex one by fixing certain of its parameters. At best, this represents a small fraction of cases in which simplicity has been thought to play a role.
iv. Simplicity as a Fundamental A Priori Principle
In the light of the perceived failure of philosophers to justify the claim that simpler theories are more likely to true, Richard Swinburne (2001) has argued that this claim has to be regarded as a fundamental a priori principle. Swinburne argues that it is just obvious that the criteria for theory evaluation that scientists use reliably lead them to make correct judgments about which theories are more likely to true. Since, Swinburne argues, one of these is that simpler theories are, other things being equal, more likely to be true, we just have to accept that simplicity is indeed an indicator of probable truth. However, Swinburne doesn’t think that this connection between simplicity and truth can be established empirically, nor does he think that it can be shown to follow from some more obvious a priori principle. Hence, we have no choice but to regard it as a fundamental a priori principle—a principle that cannot be justified by anything more fundamental.
In response to Swinburne, it can be argued that this is hardly going to convince those scientists and philosophers for whom it is not at all obvious the simpler theories are more likely to be true.
b. Alternative Justifications
i. Falsifiability
Famously, Karl Popper (1959) rejected the idea that theories are ever confirmed by evidence and that we are ever entitled to regard a theory as true, or probably true. Hence, Popper did not think simplicity could be legitimately regarded as an indicator of truth. Rather, he argued that simpler theories are to be valued because they are more falsifiable. Indeed, Popper thought that the simplicity of theories could be measured in terms of their falsifiability, since intuitively simpler theories have greater empirical content, placing more restriction on the ways the world can be, thus leading to a reduced ability to accommodate any future that we might discover. According to Popper, scientific progress consists not in the attainment of true theories, but in the elimination of false ones. Thus, the reason we should prefer more falsifiable theories is because such theories will be more quickly eliminated if they are in fact false. Hence, the practice of first considering the simplest theory consistent with the data provides a faster route to scientific progress. Importantly, for Popper, this meant that we should prefer simpler theories because they have a lower probability of being true, since, for any set of data, it is more likely that some complex theory (in Popper’s sense) will be able to accommodate it than a simpler theory.
Popper’s equation of simplicity with falsifiability suffers from some well-known objections and counter-examples, and these pose significant problems for his justificatory proposal (Section 3c). Another significant problem is that taking degree of falsifiability as a criterion for theory choice seems to lead to absurd consequences, since it encourages us to prefer absurdly specific scientific theories to those that have more general content. For instance, the hypothesis, “all emeralds are green until 11pm today when they will turn blue” should be judged as preferable to “all emeralds are green” because it is easier to falsify. It thus seems deeply implausible to say that selecting and testing such hypotheses first provides the fastest route to scientific progress.
ii. Simplicity as an Explanatory Virtue
A number of philosophers have sought to elucidate the rationale for preferring simpler theories to more complex ones in explanatory terms (for example, Friedman, 1974; Sober, 1975; Walsh, 1979; Thagard, 1988; Kitcher, 1989; Baker, 2003). These proposals have typically been made on the back of accounts of scientific explanation that explicate notions of explanatoriness and explanatory power in terms of unification, which is taken to be intimately bound up with notions of simplicity. According to unification accounts of explanation, a theory is explanatory if it shows how different phenomena are related to each other under certain systematizing theoretical principles, and a theory is held to have greater explanatory power than its rivals if it systematizes more phenomena. For Michael Friedman (1974), for instance, explanatory power is a function of the number of independent phenomena that we need to accept as ultimate: the smaller the number of independent phenomena that are regarded as ultimate by the theory, the more explanatory is the theory. Similarly, for Philip Kitcher (1989), explanatory power is increased the smaller the number of patterns of argument, or “problem-solving schemas”, that are needed to deliver the facts about the world that we accept. Thus, on such accounts, explanatory power is seen as a structural relationship between the sparseness of an explanation—the fewness of hypotheses or argument patterns—and the plenitude of facts that are explained. There have been various attempts to explicate notions of simplicity in terms of these sorts of features. A standard type of argument that is then used is that we want our theories not only to be true, but also explanatory. If truth were our only goal, there would be no reason to prefer a genuine scientific theory to a collection of random factual statements that all happen to be true. Hence, explanation is an ultimate, rather than a purely instrumental goal of scientific inquiry. Thus, we can justify our preferences for simpler theories once we recognize that there is a fundamental link between simplicity and explanatoriness and that explanation is a key goal of scientific inquiry, alongside truth.
There are some well-known objections to unification theories of explanation, though most of them concern the claim that unification is all there is to explanation—a claim on which the current proposal does not depend. However, even if we accept a unification theory of explanation and accept that explanation is an ultimate goal of scientific inquiry, it can be objected that the choice between a simple theory and a more complex rival is not normally a choice between a theory that is genuinely explanatory, in this sense, and a mere factual report. The complex theory can normally be seen as unifying different phenomena under systematizing principles, at least to some degree. Hence, the justificatory question here is not about why we should prefer theories that explain the data to theories that do not, but why we should prefer theories that have greater explanatory power in the senses just described to theories that are comparatively less explanatory. It is certainly a coherent possibility that the truth may turn out to be relatively disunified and unsystematic. Given this, it seems appropriate to ask why we are justified in choosing theories because they are more unifying. Just saying that explanation is an ultimate goal of scientific inquiry does not seem to be enough.
iii. Predictive Accuracy
In the last few decades, the treatment of simplicity as an explicit part of statistical methodology has become increasingly sophisticated. A consequence of this is that some philosophers of science have started looking to the statistics literature for illumination on how to think about the philosophical problems surrounding simplicity. According to Malcolm Forster and Elliott Sober (Forster and Sober, 1994; Forster, 2001; Sober, 2007), the work of the statistician, Hirotugu Akaike (1973), provides a precise theoretical framework for understanding the justification for the role of simplicity in curve-fitting and model selection.
Standard approaches to curve-fitting effect a trade-off between fit to a sample of data and the simplicity of the kind of mathematical relationship that is posited to hold between the variables—that is, the simplicity of the postulated model for the underlying relationship, typically measured in terms of the number of adjustable parameters it contains. This often means, for instance, that a linear hypothesis that fits a sample of data less well may be chosen over a parabolic hypothesis that fits the data better. According to Forster and Sober, Akaike developed an explanation for why it is rational to favor simpler models, under specific circumstances. The proposal builds on the practical wisdom that when there is a particular amount of error or noise in the data sample, more complex models have a greater propensity to “over-fit” to this spurious data in the sample and thus lead to less accurate predictions of extra-sample (for instance, future) data, particularly when dealing with small sample sizes. (Gauch [2003, 2006] calls this “Ockham’s hill”: to the left of the peak of the hill, increasing the complexity of a model improves its accuracy with respect to extra-sample data; after the peak, increasing complexity actually diminishes predictive accuracy. There is therefore an optimal trade-off at the peak of Ockham’s hill between simplicity and fit to the data sample when it comes to facilitating accurate prediction). According to Forster and Sober, what Akaike did was prove a theorem, which shows that, given standard statistical assumptions, we can estimate the degree to which constraining model complexity when fitting a curve to a sample of data will lead to more accurate predictions of extra-sample data. Following Forster and Sober’s presentation (1994, p9-10), Akaike’s theorem can be stated as follows:
- Estimated[A(M)] = (1/N)[log-likelihood(L(M)) – k],
where A(M) is the predictive accuracy of the model, M, with respect to extra-sample data, N is the number of data points in the sample, log-likelihood is a measure of goodness of fit to the sample (the higher the log-likelihood score the closer the fit to the data), L(M) is the best fitting member of M, and k is the number of adjustable parameters that M contains. Akaike’s theorem is claimed to specify an unbiased estimator of predictive accuracy, which means that the distribution of estimates of A is centered around the true value of A (for proofs and further details on the assumptions behind Akaike’s theorem, see Sakamoto and others, 1986). This gives rise to a model selection procedure, Akaike’s Information Criterion (AIC), which says that we should choose the model that has the highest estimated predictive accuracy, given the data at hand. In practice, AIC implies that when the best-fitting parabola fits the data sample better than the best-fitting straight line, but not so much better that this outweighs its greater complexity (k), the straight line should be used for making predictions. Importantly, the penalty imposed on complexity has less influence on model selection the larger the sample of data, meaning that simplicity matters more for predictive accuracy when dealing with smaller samples.
Forster and Sober argue that Akaike’s theorem explains why simplicity has a quantifiable positive effect on predictive accuracy by combating the risk of over-fitting to noisy data. Hence, if one is interested in generating accurate predictions—for instance, of future data—one has a clear rationale for preferring simpler models. Forster and Sober are explicit that this proposal is only meant to apply to scientific contexts that can be understood from within a model selection framework, where predictive accuracy is the central goal of inquiry and there is a certain amount of error or noise in the data. Hence, they do not view Akaike’s work as offering a complete solution to the problem of justifying preferences for simpler theories. However, they have argued that a very significant number of scientific inference problems can be understood from an Akaikian perspective.
Several objections have been raised against Forster and Sober’s philosophical use of Akaike’s work. One objection is that the measure of simplicity employed by AIC is not language invariant, since the number of adjustable parameters a model contains depends on how the model is described. However, Forster and Sober argue that though, for practical purposes, the quantity, k, is normally spelt out in terms of number of adjustable parameters, it is in fact more accurately explicated in terms of the notion of the dimension of a family of functions, which is language invariant. Another objection is that AIC is not statistically consistent. Forster and Sober reply that this charge rests on a confusion over what AIC is meant to estimate: for example, erroneously assuming that AIC is meant to be estimator of the true value of k (the size of the simplest model that contains the true hypothesis), rather than an estimator of the predictive accuracy of a particular model at hand. Another worry is that over-fitting considerations imply that an idealized false model will often make more accurate predictions than a more realistic model, so the justification is merely instrumentalist and cannot warrant the use of simplicity as a criterion for hypothesis acceptance where hypotheses are construed realistically, rather than just as predictive tools. For their part, Forster and Sober are quite happy to accept this instrumentalist construal of the role of simplicity in curve-fitting and model selection: in this context, simplicity is not a guide to the truth, but to predictive accuracy. Finally, there are a variety of objections concerning the nature and validity of the assumptions behind Akaikie’s theorem and whether AIC is applicable to some important classes of model selection problems (for discussion, see Kieseppä, 1997; Forster, 1999, 2001; Howson and Urbach, 2006; Dowe and others, 2007; Sober, 2007; Kelly, 2010).
iv. Truth-Finding Efficiency
An important recent proposal about how to justify preferences for simpler theories has come from work in the interdisciplinary field known as formal learning theory (Schulte, 1999; Kelly, 2004, 2007, 2010). It has been proposed that even if we do not know whether the world is simple or complex, inferential rules that are biased towards simple hypotheses can be shown to converge to the truth more efficiently than alternative inferential rules. According to this proposal, an inferential rule is said to converge to the truth efficiently, if, relative to other possible convergent inferential rules, it minimizes the maximum number of U-turns or “retractions” of opinion that might be required of the inquirer while using the rule to guide her decisions on what to believe given the data. Such procedures are said to converge to the truth more directly and in a more stable fashion, since they require fewer changes of mind along the way. The proposal is that even if we do not know whether the truth is simple or complex, scientific inference procedures that are biased towards simplicity can be shown a priori to be optimally efficient in this sense, converging to the truth in the most direct and stable way possible.
To illustrate the basic logic behind this proposal, consider the following example from Oliver Schulte (1999). Suppose that we are investigating the existence of hypothetical particle, Ω. If Ω does exist, we will be able to detect it with an appropriate measurement device. However, as yet, it has not been detected. What attitude should we take towards the existence Ω? Let us say that Ockham’s Razor suggests that we deny that Ω exists until it is detected (if ever). Alternatively, we could assert that Ω does exist until a finite number of attempts to detect Ω have proved to be unsuccessful, say ten thousand, in which case, we assert that Ω does not exist; or, we could withhold judgment until Ω is either detected, or there have been ten thousand unsuccessful attempts to detect it. Since we are assuming that existent particles do not go undetected forever, abiding by any of three of these inferential rules will enable us to converge to the truth in the limit, whether Ω exists or not. However, Schulte argues that Ockham’s Razor provides the most efficient route to the truth. This is because following Ockham’s Razor incurs a maximum of only one retraction of opinion: retracting an assertion of non-existence to an assertion of existence, if Ω is detected. In contrast, the alternative inferential rules both incur a maximum of two retractions, since Ω could go undetected ten thousand times, but is then detected on the ten thousandth and one time. Hence, truth-finding efficiency requires that one adopt Ockham’s Razor and presume that Ω does not exist until it is detected.
Kevin Kelly has further developed this U-turn argument in considerable detail. Kelly argues that, with suitable refinements, it can be extended to an extremely wide variety of real world scientific inference problems. Importantly, Kelly has argued that, on this proposal, simplicity should not be seen as purely a pragmatic consideration in theory choice. While simplicity cannot be regarded as a direct indicator of truth, we do nonetheless have a reason to think that the practice of favoring simpler theories is a truth-conducive strategy, since it promotes speedy and stable attainment of true beliefs. Hence, simplicity should be regarded as a genuinely epistemic consideration in theory choice.
One worry about the truth-finding efficiency proposal concerns the general applicability of these results to scientific contexts in which simplicity may play a role. The U-turn argument for Ockham’s razor described above seems to depend on the evidential asymmetry between establishing that Ω exists and establishing that Ω does not exist: a detection of Ω is sufficient to establish the existence of Ω, whereas repeated failures of detection are not sufficient to establish non-existence. The argument may work where detection procedures are relatively clear-cut—for instance where there are relatively unambiguous instrument readings that count as “detections”—but what about entities that are very difficult to detect directly and where mistakes can easily be made about existence as well as non-existence? Similarly, a current stumbling block is that the U-turn argument cannot be used as a justification for the employment of simplicity biases in statistical inference, where the hypotheses under consideration do not have deductive observational consequences. Kelly is, however, optimistic about extending the U-turn argument to statistical inference. Another objection concerns the nature of the justification that is being provided here. What the U-turn argument seems to show is that the strategy of favoring the simplest theory consistent with the data may help one to find the truth with fewer reversals along the way. It does not establish that simpler theories themselves should be regarded as in any way “better” than their more complex rivals. Hence, there are doubts about the extent to which this proposal can actually make sense of standard examples of simplicity preferences at work in the history and current practice of science, where the guiding assumption seems to be that simpler theories are not to be preferred merely for strategic reasons, but because they are better theories.
c. Deflationary Approaches
Various philosophers have sought to defend broadly deflationary accounts of simplicity. Such accounts depart from all of the justificatory accounts discussed so far by rejecting the idea that simplicity should in fact be regarded as a theoretical virtue and criterion for theory choice in its own right. Rather, according to deflationary accounts, when simplicity appears to be a driving factor in theory evaluation, something else is doing the real work.
Richard Boyd (1990), for instance, has argued that scientists’ simplicity judgments are typically best understood as just covert judgements of theoretical plausibility. When a scientist claims that one theory is “simpler” than another this is often just another way of saying that the theory provides a more plausible account of the data. For Boyd, such covert judgments of theoretical plausibility are driven by the scientist’s background theories. Hence, it is the relevant background theories that do the real work in motivating the preference for the “simpler” theory, not the simplicity of the theory per se. John Norton (2003) has advocated a similar view in the context of his “material theory” of induction, according to which inductive inferences are licensed not by universal inductive rules or inference schemas, but rather by local factual assumptions about the domain of inquiry. Norton argues that the apparent use of simplicity in induction merely reflects material assumptions about the nature of the domain being investigated. For instance, when we try to fit curves to data we choose the variables and functions that we believe to be appropriate to the physical reality we are trying to get at. Hence, it is because of the facts that we believe to prevail in this domain that we prefer a “simple” linear function to a quadratic one, if such a curve fits the data sufficiently well. In a different domain, where we believe that different facts prevail, our decision about which hypotheses are “simple” or “complex” are likely to be very different.
Elliott Sober (1988, 1994) has defended this sort of deflationary analysis of various appeals to simplicity and parsimony in evolutionary biology. For example, Sober argues that the common claim that group selection hypotheses are “less parsimonious” and hence to be taken less seriously as explanations for biological adaptations than individual selection hypotheses, rests on substantive assumptions about the comparative rarity of the conditions required for group selection to occur. Hence, the appeal to Ockham’s Razor in this context is just a covert appeal to local background knowledge. Other attempts to offer deflationary analyses of particular appeals to simplicity in science include Plutynski (2005), who focuses on the Fisher-Wright debate in evolutionary biology, and Fitzpatrick (2009), who focuses on appeals to simplicity in debates over the cognitive capacities of non-human primates.
If such deflationary analyses of the putative role of simplicity in particular scientific contexts turn out to be plausible, then problems concerning how to measure simplicity and how to offer a general justification for preferring simpler theories can be avoided, since simplicity per se can be shown to do no substantive work in the relevant inferences. However, many philosophers are skeptical that such deflationary analyses are possible for many of the contexts where simplicity considerations have been thought to play an important role. Kelly (2010), for example, has argued that simplicity typically comes into play when our background knowledge underdetermines theory choice. Sober himself seems to advocate a mixed view: some appeals to simplicity in science are best understood in deflationary terms, others are better understood in terms of Akaikian model selection theory.
5. Conclusion
The putative role of considerations of simplicity in the history and current practice of science gives rise to a number of philosophical problems, including the problem of precisely defining and measuring theoretical simplicity, and the problem of justifying preferences for simpler theories. As this survey of the literature on simplicity in the philosophy of science demonstrates, these problems have turned out to be surprisingly resistant to resolution, and there remains a live debate amongst philosophers of science about how to deal with them. On the other hand, there is no disputing the fact that practicing scientists continue to find it useful to appeal to various notions of simplicity in their work. Thus, in many ways, the debate over simplicity resembles other long-running debates in the philosophy science, such as that over the justification for induction (which, it turns out, is closely related to the problem of justifying preferences for simpler theories). Though there is arguably more skepticism within the scientific community about the legitimacy of choosing between rival theories on grounds of simplicity than there is about the legitimacy of inductive inference—the latter being a complete non-issue for practicing scientists—as is the case with induction, very many scientists continue to employ practices and methods that utilize notions of simplicity to great scientific effect, assuming that appropriate solutions to the philosophical problems that these practices give rise to do in fact exist, even though philosophers have so far failed to articulate them. However, as this survey has also shown, statisticians, information and learning theorists, and other scientists have been making increasingly important contributions to the debate over the philosophical underpinning for these practices.
6. References and Further Reading
- Ackerman, R. 1961. Inductive simplicity. Philosophy of Science, 28, 162-171.
- Argues against the claim that simplicity considerations play a significant role in inductive inference. Critiques measures of simplicity proposed by Jeffreys, Kemeny, and Popper.
- Akaike, H. 1973. Information theory and the extension of the maximum likelihood principle. In B. Petrov and F. Csaki (eds.), Second International Symposium on Information Theory. Budapest: Akademiai Kiado.
- Laid the foundations for model selection theory. Proves a theorem suggesting that the simplicity of a model is relevant to estimating its future predictive accuracy. Highly technical.
- Baker, A. 2003. Quantitative parsimony and explanatory power. British Journal for the Philosophy of Science, 54, 245-259.
- Builds on Nolan (1997), argues that quantitative parsimony is linked with explanatory power.
- Baker, A. 2007. Occam’s Razor in science: a case study from biogeography. Biology and Philosophy, 22, 193-215.
- Argues for a “naturalistic” justification of Ockham’s Razor and that preferences for ontological parsimony played a significant role in the late 19th century debate in bio-geography between dispersalist and extensionist theories.
- Barnes, E.C. 2000. Ockham’s razor and the anti-superfluity principle. Erkenntnis, 53, 353-374.
- Draws a useful distinction between two different interpretations of Ockham’s Razor: the anti-superfluity principle and the anti-quantity principle. Explicates an evidential justification for anti-superfluity principle.
- Boyd, R. 1990. Observations, explanatory power, and simplicity: towards a non-Humean account. In R. Boyd, P. Gasper and J.D. Trout (eds.), The Philosophy of Science. Cambridge, MA: MIT Press.
- Argues that appeals to simplicity in theory evaluation are typically best understood as covert judgments of theoretical plausibility.
- Bunge, M. 1961. The weight of simplicity in the construction and assaying of scientific theories. Philosophy of Science, 28, 162-171.
- Takes a skeptical view about the importance and justifiability of a simplicity criterion in theory evaluation.
- Carlson, E. 1966. The Gene: A Critical History. Philadelphia: Saunders.
- Argues that simplicity considerations played a significant role in several important debates in the history of genetics.
- Carnap, R. 1950. Logical Foundations of Probability. Chicago: University of Chicago Press.
- Chater, N. 1999. The search for simplicity: a fundamental cognitive principle. The Quarterly Journal of Experimental Psychology, 52A, 273-302.
- Argues that simplicity plays a fundamental role in human reasoning, with simplicity to be defined in terms of Kolmogorov complexity.
- Cohen, I.B. 1985. Revolutions in Science. Cambridge, MA: Harvard University Press.
- Cohen, I.B. 1999. A guide to Newton’s Principia. In I. Newton, The Principia: Mathematical Principles of Natural Philosophy; A New Translation by I. Bernard Cohen and Anne Whitman. Berkeley: University of California Press.
- Crick, F. 1988. What Mad Pursuit: a Personal View of Scientific Discovery. New York: Basic Books.
- Argues that the application of Ockham’s Razor to biology is inadvisable.
- Dowe, D, Gardner, S., and Oppy, G. 2007. Bayes not bust! Why simplicity is no problem for Bayesians. British Journal for the Philosophy of Science, 58, 709-754.
- Contra Forster and Sober (1994), argues that Bayesians can make sense of the role of simplicity in curve-fitting.
- Duhem, P. 1954. The Aim and Structure of Physical Theory. Princeton: Princeton University Press.
- Einstein, A. 1954. Ideas and Opinions. New York: Crown.
- Einstein’s views about the role of simplicity in physics.
- Fitzpatrick, S. 2009. The primate mindreading controversy: a case study in simplicity and methodology in animal psychology. In R. Lurz (ed.), The Philosophy of Animal Minds. New York: Cambridge University Press.
- Advocates a deflationary analysis of appeals to simplicity in debates over the cognitive capacities of non-human primates.
- Forster, M. 1995. Bayes and bust: simplicity as a problem for a probabilist’s approach to confirmation. British Journal for the Philosophy of Science, 46, 399-424.
- Argues that the Bayesian approach to scientific reasoning is inadequate because it cannot make sense of the role of simplicity in theory evaluation.
- Forster, M. 1999. Model selection in science: the problem of language variance. British Journal for the Philosophy of Science, 50, 83-102.
- Responds to criticisms of Forster and Sober (1994). Argues that AIC relies on a language invariant measure of simplicity.
- Forster, M. 2001. The new science of simplicity. In A. Zellner, H. Keuzenkamp and M. McAleer (eds.), Simplicity, Inference and Modelling. Cambridge: Cambridge University Press.
- Accessible introduction to model selection theory. Describes how different procedures, including AIC, BIC, and MDL, trade-off simplicity and fit to the data.
- Forster, M. and Sober, E. 1994. How to tell when simpler, more unified, or less ad hoc theories will provide more accurate predictions. British Journal for the Philosophy of Science, 45, 1-35.
- Explication of AIC statistics and its relevance to the philosophical problem of justifying preferences for simpler theories. Argues against Bayesian approaches to simplicity. Technical in places.
- Foster, M. and Martin, M. 1966. Probability, Confirmation, and Simplicity: Readings in the Philosophy of Inductive Logic. New York: The Odyssey Press.
- Anthology of papers discussing the role of simplicity in induction. Contains important papers by Ackermann, Barker, Bunge, Goodman, Kemeny, and Quine.
- Friedman, M. 1974. Explanation and scientific understanding. Journal of Philosophy, LXXI, 1-19.
- Defends a unification account of explanation, connects simplicity with explanatoriness.
- Galilei, G. 1962. Dialogues concerning the Two Chief World Systems. Berkeley: University of California Press.
- Classic defense of Copernicanism with significant emphasis placed on the greater simplicity and harmony of the Copernican system. Asserts that nature does nothing in vain.
- Gauch, H. 2003. Scientific Method in Practice. Cambridge: Cambridge University Press.
- Wide-ranging discussion of the scientific method written by a scientist for scientists. Contains a chapter on the importance of parsimony in science.
- Gauch, H. 2006. Winning the accuracy game. American Scientist, 94, March-April 2006, 134-141.
- Useful informal presentation of the concept of Ockham’s hill and its importance to scientific research in a number of fields.
- Gingerich, O. 1993. The Eye of Heaven: Ptolemy, Copernicus, Kepler. New York: American Institute of Physics.
- Glymour, C. 1980. Theory and Evidence. Princeton: Princeton University Press.
- An important critique of Bayesian attempts to make sense of the role of simplicity in science. Defends a “boot-strapping” analysis of the simplicity arguments for Copernicanism and Newton’s argument for universal gravitation.
- Goodman, N. 1943. On the simplicity of ideas. Journal of Symbolic Logic, 8, 107-1.
- Goodman, N. 1955. Axiomatic measurement of simplicity. Journal of Philosophy, 52, 709-722.
- Goodman, N. 1958. The test of simplicity. Science, 128, October 31st 1958, 1064-1069.
- Reasonably accessible introduction to Goodman’s attempts to formulate a measure of logical simplicity.
- Goodman, N. 1959. Recent developments in the theory of simplicity. Philosophy and Phenomenological Research, 19, 429-446.
- Response to criticisms of Goodman (1955).
- Goodman, N. 1961. Safety, strength, simplicity. Philosophy of Science, 28, 150-151.
- Argues that simplicity cannot be equated with testability, empirical content, or paucity of assumption.
- Goodman, N. 1983. Fact, Fiction and Forecast (4th edition). Cambridge, MA: Harvard University Press.
- Harman, G. 1999. Simplicity as a pragmatic criterion for deciding what hypotheses to take seriously. In G. Harman, Reasoning, Meaning and Mind. Oxford: Oxford University Press.
- Defends the claim that simplicity is a fundamental component of inductive inference and that this role has a pragmatic justification.
- Harman, G. and Kulkarni, S. 2007. Reliable Reasoning: Induction and Statistical Learning Theory. Cambridge, MA: MIT Press.
- Accessible introduction to statistical learning theory and VC dimension.
- Harper, W. 2002. Newton’s argument for universal gravitation. In I.B. Cohen and G.E. Smith (eds.), The Cambridge Companion to Newton. Cambridge: Cambridge University Press.
- Hesse, M. 1967. Simplicity. In P. Edwards (ed.), The Encyclopaedia of Philosophy, vol. 7. New York: Macmillan.
- Focuses on attempts by Jeffreys, Popper, Kemeny, and Goodman to formulate measures of simplicity.
- Hesse, M. 1974. The Structure of Scientific Inference. London: Macmillan.
- Defends the view that simplicity is a determinant of prior probability. Useful discussion of the role of simplicity in Einstein’s work.
- Holton, G. 1974. Thematic Origins of Modern Science: Kepler to Einstein. Cambridge, MA: Harvard University Press.
- Discusses the role of aesthetic considerations, including simplicity, in the history of science.
- Hoffman, R., Minkin, V., and Carpenter, B. 1997. Ockham’s Razor and chemistry. Hyle, 3, 3-28.
- Discussion by three chemists of the benefits and pitfalls of applying Ockham’s Razor in chemical research.
- Howson, C. and Urbach, P. 2006. Scientific Reasoning: The Bayesian Approach (Third Edition). Chicago: Open Court.
- Contains a useful survey of Bayesian attempts to make sense of the role of simplicity in theory evaluation. Technical in places.
- Jeffreys, H. 1957. Scientific Inference (2nd edition). Cambridge: Cambridge University Press.
- Defends the “simplicity postulate” that simpler theories have higher prior probability.
- Jeffreys, H. 1961. Theory of Probability. Oxford: Clarendon Press.
- Outline and defense of the Bayesian approach to scientific inference. Discusses the role of simplicity in the determination of priors and likelihoods.
- Kelly, K. 2004. Justification as truth-finding efficiency: how Ockham’s Razor works. Minds and Machines, 14, 485-505.
- Argues that Ockham’s Razor is justified by considerations of truth-finding efficiency. Critiques Bayesian, Akiakian, and other traditional attempts to justify simplicity preferences. Technical in places.
- Kelly, K. 2007. How simplicity helps you find the truth without pointing at it. In M. Friend, N. Goethe, and V.Harizanov (eds.), Induction, Algorithmic Learning Theory, and Philosophy. Dordrecht: Springer.
- Refinement and development of the argument found in Kelly (2004) and Schulte (1999). Technical.
- Kelly, K. 2010. Simplicity, truth and probability. In P. Bandyopadhyay and M. Forster (eds.), Handbook of the Philosophy of Statistics. Dordrecht: Elsevier.
- Expands and develops the argument found in Kelly (2007). Detailed critique of Bayesian accounts of simplicity. Technical.
- Kelly, K. and Glymour, C. 2004. Why probability does not capture the logic of scientific justification. In C. Hitchcock (ed.), Contemporary Debates in the Philosophy of Science. Oxford: Blackwell.
- Argues that Bayesians can’t make sense of Ockham’s Razor.
- Kemeny, J. 1955. Two measures of complexity. Journal of Philosophy, 52, p722-733.
- Develops some of Goodman’s ideas about how to measure the logical simplicity of predicates and systems of predicates. Proposes a measure of simplicity similar to Popper’s (1959) falsifiability measure.
- Kieseppä, I. A. 1997. Akaike Information Criterion, curve-fitting, and the philosophical problem of simplicity. British Journal for the Philosophy of Science, 48, p21-48.
- Critique of Forster and Sober (1994). Argues that Akaike’s theorem has little relevance to traditional philosophical problems surrounding simplicity. Highly technical.
- Kitcher, P. 1989. Explanatory unification and the causal structure of the world. In P. Kitcher and W. Salmon, Minnesota Studies in the Philosophy of Science, vol 13: Scientific Explanation, Minneapolis: University of Minnesota Press.
- Defends a unification theory of explanation. Argues that simplicity contributes to explanatory power.
- Kuhn, T. 1957. The Copernican Revolution. Cambridge, MA: Harvard University Press.
- Influential discussion of the role of simplicity in the arguments for Copernicanism.
- Kuhn, T. 1962. The Structure of Scientific Revolutions. Chicago: University of Chicago Press.
- Kuipers, T. 2002. Beauty: a road to truth. Synthese, 131, 291-328.
- Attempts to show how aesthetic considerations might be indicative of truth.
- Kyburg, H. 1961. A modest proposal concerning simplicity. Philosophical Review, 70, 390-395.
- Important critique of Goodman (1955). Argues that simplicity be identified with the number of quantifiers in a theory.
- Lakatos, I. and Zahar, E. 1978. Why did Copernicus’s research programme supersede Ptolemy’s? In J. Worrall and G. Curie (eds.), The Methodology of Scientific Research Programmes: Philosophical Papers of Imre Lakatos, Volume 1. Cambridge: Cambridge University Press.
- Argues that simplicity did not really play a significant role in the Copernican Revolution.
- Lewis, D. 1973. Counterfactuals. Oxford: Basil Blackwell.
- Argues that quantitative parsimony is less important than qualitative parsimony in scientific and philosophical theorizing.
- Li, M. and Vitányi, P. 1997. An Introduction to Kolmogorov Complexity and its Applications (2nd edition). New York: Springer.
- Detailed elaboration of Kolmogorov complexity as a measure of simplicity. Highly technical.
- Lipton, P. 2004. Inference to the Best Explanation (2nd edition). Oxford: Basil Blackwell.
- Account of inference to the best explanation as inference to the “loveliest” explanation. Defends the claim that simplicity contributes to explanatory loveliness.
- Lombrozo, T. 2007. Simplicity and probability in causal explanation. Cognitive Psychology, 55, 232–257.
- Argues that simplicity is used as a guide to assessing the probability of causal explanations.
- Lu, H., Yuille, A., Liljeholm, M., Cheng, P. W., and Holyoak, K. J. 2006. Modeling causal learning using Bayesian generic priors on generative and preventive powers. In R. Sun and N. Miyake (eds.), Proceedings of the 28th annual conference of the cognitive science society, 519–524. Mahwah, NJ: Erlbaum.
- Argues that simplicity plays a significant role in causal learning.
- MacKay, D. 1992. Bayesian interpolation. Neural Computation, 4, 415-447.
- First presentation of the concept of Ockham’s Hill.
- Martens, R. 2009. Harmony and simplicity: aesthetic virtues and the rise of testability. Studies in History and Philosophy of Science, 40, 258-266.
- Discussion of the Copernican simplicity arguments and recent attempts to reconstruct the justification for them.
- McAlleer, M. 2001. Simplicity: views of some Nobel laureates in economic science. In A. Zellner, H. Keuzenkamp and M. McAleer (eds.), Simplicity, Inference and Modelling. Cambridge: Cambridge University Press.
- Interesting survey of the views of famous economists on the place of simplicity considerations in their work.
- McAllister, J. W. 1996. Beauty and Revolution in Science. Ithaca: Cornell University Press.
- Proposes that scientists’ simplicity preferences are the product of an aesthetic induction.
- Mill, J.S. 1867. An Examination of Sir William Hamilton’s Philosophy. London: Walter Scott.
- Myrvold, W. 2003. A Bayesian account of the virtue of unification. Philosophy of Science, 70, 399-423.
- Newton, I. 1999. The Principia: Mathematical Principles of Natural Philosophy; A New Translation by I. Bernard Cohen and Anne Whitman. Berkeley: University of California Press.
- Contains Newton’s “rules for the study of natural philosophy”, which includes a version of Ockham’s Razor, defended in terms of the simplicity of nature. These rules play an explicit role in Newton’s argument for universal gravitation.
- Nolan, D. 1997. Quantitative Parsimony. British Journal for the Philosophy of Science, 48, 329-343.
- Contra Lewis (1973), argues that quantitative parsimony has been important in the history of science.
- Norton, J. 2000. ‘Nature is the realization of the simplest conceivable mathematical ideas’: Einstein and canon of mathematical simplicity. Studies in the History and Philosophy of Modern Physics, 31, 135-170.
- Discusses the evolution of Einstein’s thinking about the role of mathematical simplicity in physical theorizing.
- Norton, J. 2003. A material theory of induction. Philosophy of Science, 70, p647-670.
- Defends a “material” theory of induction. Argues that appeals to simplicity in induction reflect factual assumptions about the domain of inquiry.
- Oreskes, N., Shrader-Frechette, K., Belitz, K. 1994. Verification, validation, and confirmation of numerical models in the earth sciences. Science, 263, 641-646.
- Palter, R. 1970. An approach to the history of early astronomy. Studies in History and Philosophy of Science, 1, 93-133.
- Pais, A. 1982. Subtle Is the Lord: The science and life of Albert Einstein. Oxford: Oxford University Press.
- Peirce, C.S. 1931. Collected Papers of Charles Sanders Peirce, vol 6. C. Hartshorne, P. Weiss, and A. Burks (eds.). Cambridge, MA: Harvard University Press.
- Plutynski, A. 2005. Parsimony and the Fisher-Wright debate. Biology and Philosophy, 20, 697-713.
- Advocates a deflationary analysis of appeals to parsimony in debates between Wrightian and neo-Fisherian models of natural selection.
- Popper, K. 1959. The Logic of Scientific Discovery. London: Hutchinson.
- Argues that simplicity = empirical content = falsifiability.
- Priest, G. 1976. Gruesome simplicity. Philosophy of Science, 43, 432-437.
- Shows that standard measures of simplicity in curve-fitting are language variant.
- Raftery, A., Madigan, D., and Hoeting, J. 1997. Bayesian model averaging for linear regression models. Journal of the American Statistical Association, 92, 179-191.
- Reichenbach, H. 1949. On the justification of induction. In H. Feigl and W. Sellars (eds.), Readings in Philosophical Analysis. New York: Appleton-Century-Crofts.
- Rosencrantz, R. 1983. Why Glymour is a Bayesian. In J. Earman (ed.), Testing Scientific Theories. Minneapolis: University of Minnesota Press.
- Responds to Glymour (1980). Argues that simpler theories have higher likelihoods, using Copernican vs. Ptolemaic astronomy as an example.
- Rothwell, G. 2006. Notes for the occasional major case manager. FBI Law Enforcement Bulletin, 75, 20-24.
- Emphasizes the importance of Ockham’s Razor in criminal investigation.
- Sakamoto, Y., Ishiguro, M., and Kitagawa, G. 1986. Akaike Information Criterion Statistics. New York: Springer.
- Schaffner, K. 1974. Einstein versus Lorentz: research programmes and the logic of comparative theory evaluation. British Journal for the Philosophy of Science, 25, 45-78.
- Argues that simplicity played a significant role in the development and early acceptance of special relativity.
- Schulte, O. 1999. Means-end epistemology. British Journal for the Philosophy of Science, 50, 1-31.
- First statement of the claim that Ockham’s Razor can be justified in terms of truth-finding efficiency.
- Simon, H. 1962. The architecture of complexity. Proceedings of the American Philosophical Society, 106, 467-482.
- Important discussion by a Nobel laureate of features common to complex systems in nature.
- Sober, E. 1975. Simplicity. Oxford: Oxford University Press.
- Argues that simplicity can be defined in terms of question-relative informativeness. Technical in places.
- Sober, E. 1981. The principle of parsimony. British Journal for the Philosophy of Science, 32, 145-156.
- Distinguishes between “agnostic” and “atheistic” versions of Ockham’s Razor. Argues that the atheistic razor has an inductive justification.
- Sober, E. 1988. Reconstructing the Past: Parsimony, Evolution and Inference. Cambridge, MA: MIT Press.
- Defends a deflationary account of simplicity in the context of the use of parsimony methods in evolutionary biology.
- Sober, E. 1994. Let’s razor Ockham’s Razor. In E. Sober, From a Biological Point of View, Cambridge: Cambridge University Press.
- Argues that the use of Ockham’s Razor is grounded in local background assumptions.
- Sober, E. 2001a. What is the problem of simplicity? In H. Keuzenkamp, M. McAlleer, and A. Zellner (eds.), Simplicity, Inference and Modelling. Cambridge: Cambridge University Press.
- Sober, E. 2001b. Simplicity. In W.H. Newton-Smith (ed.), A Companion to the Philosophy of Science, Oxford: Blackwell.
- Sober, E. 2007. Evidence and Evolution. New York: Cambridge University Press.
- Solomonoff, R.J. 1964. A formal theory of inductive inference, part 1 and part 2. Information and Control, 7, 1-22, 224-254.
- Suppes, P. 1956. Nelson Goodman on the concept of logical simplicity. Philosophy of Science, 23, 153-159.
- Swinburne, R. 2001. Epistemic Justification. Oxford: Oxford University Press.
- Argues that the principle that simpler theories are more probably true is a fundamental a priori principle.
- Thagard, P. 1988. Computational Philosophy of Science. Cambridge, MA: MIT Press.
- Simplicity is a determinant of the goodness of an explanation and can be measured in terms of the paucity of auxiliary assumptions relative to the number of facts explained.
- Thorburn, W. 1918. The myth of Occam’s Razor. Mind, 23, 345-353.
- Argues that William of Ockham would not have advocated many of the principles that have been attributed to him.
- van Fraassen, B. 1989. Laws and Symmetry. Oxford: Oxford University Press.
- Wallace, C. S. and Dowe, D. L. 1999. Minimum Message Length and Kolmogorov Complexity. Computer Journal, 42(4), 270–83.
- Walsh, D. 1979. Occam’s Razor: A Principle of Intellectual Elegance. American Philosophical Quarterly, 16, 241-244.
- Weinberg, S. 1993. Dreams of a Final Theory. New York: Vintage.
- Argues that physicists demand simplicity in physical principles before they can be taken seriously.
- White, R. 2005. Why favour simplicity? Analysis, 65, 205-210.
- Attempts to justify preferences for simpler theories in virtue of such theories having higher likelihoods.
- Zellner, A, Keuzenkamp, H., and McAleer, M. 2001. Simplicity, Inference and Modelling. Cambridge: Cambridge University Press.
- Collection papers by statisticians, philosophers, and economists on the role of simplicity in scientific inference and modelling.
Author Information
Simon Fitzpatrick
Email: sfitzpatrick@jcu.edu
John Carroll University
U. S. A.